极速、可扩展的主题路由 - 第一部分
除其他事项外,最近我们一直致力于提高 RabbitMQ 的路由性能。特别是,我们研究了通过使用一些著名的算法以及其他一些技巧来加速主题交换。我们能够找到比我们当前实现快许多倍的解决方案。
首先,简单介绍一下我们试图解决的问题。以下是 AMQP 0-9-1 规范的一段引用
主题交换类型的工作方式如下
- 消息队列使用路由模式 P 绑定到交换机。
- 发布者向交换机发送一条带有路由键 R 的消息。
- 如果 R 匹配 P,则将消息传递给消息队列。
用于主题交换的路由键必须由零个或多个由点分隔的单词组成。每个单词可以包含字母 A-Z 和 a-z 以及数字 0-9。
路由模式遵循与路由键相同的规则,增加了 * 匹配单个单词,而 # 匹配零个或多个单词。因此,路由模式 .stock.# 匹配路由键 usd.stock 和 eur.stock.db,但不匹配 stock.nasdaq.。我们的目标是以快速可扩展的方式将消息(路由键)与绑定(模式)进行匹配。
以下是我们尝试过的方法列表
- 按单词缓存消息的主题。这正是 AMQP 规范所建议的,并且已经有一些相关的研究。
- 按单词索引模式。这与方法 1 类似,只是我们提前准备好模式,而不是为之前发送过的所有主题键逐个准备。
- Trie 实现。将模式中的单词排列成 Trie 结构,并沿着 Trie 向下查找以查看特定主题是否匹配。
- 确定性有限自动机 (DFA) 实现。这是一种在一般情况下进行字符串匹配的著名方法。
这些方法中的每一种都有其优缺点。我们通常以以下目标为导向:
- 在空间和时间上都具有良好的复杂性,以使其可扩展
- 易于实现
- 在常用情况下的良好性能
- 良好的最坏情况性能
- 使其在简单情况下快速(当绑定数量的可扩展性不是问题时)
从一开始,仅仅通过在拆分键为单词时更加谨慎(而不是在每次每次为每个模式重复拆分模式和主题),我们就能够将所有情况下的性能提高到当前实现的 3 倍。
我们发现方法 1 和 2 特别不适合我们的需求。它们最慢,并且不具有良好的复杂性,因为它们涉及每个级别的集合相交,并且无法适应包含“#”的功能。因此,我们将注意力集中在方法 3 和 4 上。
Trie
如果我们添加模式“a.b.c”、“a.*.b.c”、“a.#.c”、“b.b.c”,则 Trie 结构示例如下

为了匹配一个模式(例如“a.d.d.d.c”),我们从根开始,逐字向下遍历树。我们可以通过精确匹配、“*”或“#”来深入。对于“#”,我们可以使用主题尾部的所有变体来深入。对于我们的示例,我们将通过“#”处理“d.d.d.c”、“d.d.c”、“d.c”、“c”和“”这几种情况。
Trie 实现有许多优点:空间复杂度好;添加新绑定成本低;并且是最容易实现的;但缺点是,为了找到所有可能的匹配,它会为“*”和“#”进行回溯。
DFA
此方法基于构建一个接受绑定模式的 NFA,然后从中构建等效的 DFA 并使用它。由于我们不仅关心它是否匹配,还关心哪个模式匹配,因此我们无法在 NFA 中合并模式的尾部。
为了构造 DFA,我们这样模拟了“#”的行为

例如,模式“a.b.c”、“a.*.b.c”、“a.#.c”、“b.b.c”将在 NFA 中这样表示
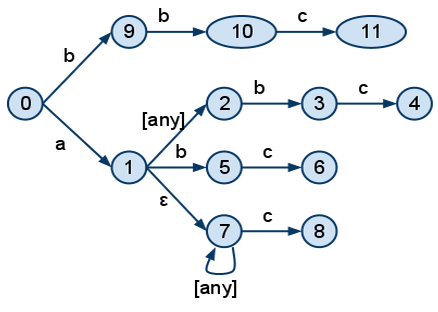
节点 11、4、6 和 8 将附加信息,指向相应的绑定。
为了将 NFA 转换为 DFA,我们尝试了各种方法,甚至生成了图后面结构的源代码,以使其尽可能快。我们最终得到的最佳解决方案是即时构建 DFA,就像在好的正则表达式编译器中一样(例如,请参阅 这篇文章)。
DFA 方法的优点是,一旦构建了 DFA,就不需要回溯。另一方面,也有相当多的缺点:它占用的内存比 Trie 多得多;添加新绑定有显着的成本,因为整个 DFA 必须被丢弃并重新构建;并且它更复杂,因此更难实现和维护。
在接下来的几篇文章中,我们将详细介绍这两种结构,它们在基准测试中的表现,它们的时间和空间复杂度,以及我们尝试过的 DFA 优化的细节。
未完待续。