RabbitMQ 性能测量,第二部分
欢迎回来!上次我们讨论了流量控制和延迟;今天,让我们来谈谈不同功能如何影响我们看到的性能。这里有一些简单的场景。和上次一样,它们都是围绕一个发布者和一个消费者以最快速度发布消息的主题进行的变体。
一些简单的场景
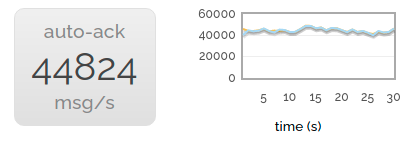
第一个场景最简单——只有一个生产者和一个消费者。这样我们就有了基线。
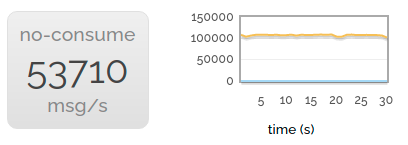
当然,我们希望获得令人印象深刻的数据。所以我们可以稍微快一点——如果我们不消费任何东西,我们就可以更快地发布。

这利用了我们服务器的几个核心——但不是全部。因此,为了获得最佳的、吸引眼球的吞吐量,我们启动了多个并行生产者,它们都发布到空。 (即不进行任何消费)。
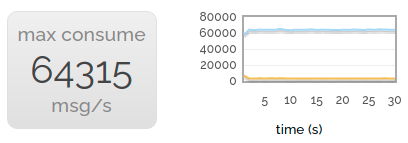
当然,消费也很重要!因此,为了获得吸引眼球的消费吞吐量,我们并行地发布到大量的消费者。
当然,在某种程度上,这种对大数字的追求有点愚蠢,我们更关心相对性能。所以让我们回到一个生产者和一个消费者。

现在让我们尝试设置 mandatory 标志进行发布。我们的吞吐量会下降到非 mandatory 速率的约 40%。原因是我们将消息发布到的通道不能再异步地将消息流式传输到队列;它会同步地与队列进行检查,以确保它们仍然存在。(是的,我们也许可以加快 mandatory 发布的速度,但它并不是被大量使用。)

immediate 标志使我们的性能下降了几乎完全相同。这并不令人惊讶——它必须与队列进行相同的同步检查。

抛开很少使用的 mandatory 和 immediate 标志,让我们尝试打开已送达消息的确认。与不带确认的消息相比,我们仍然看到性能有所下降(毕竟服务器需要做更多的簿记工作),但这不太明显。

现在我们也打开了发布确认。性能略有下降,但我们仍然达到了未进行 ack 或 confirm 的速度的 60% 以上。
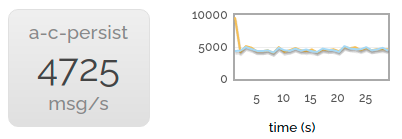
最后,我们启用了消息持久化。吞吐量大大降低,因为我们也正在将所有这些消息写入磁盘。
消息大小
值得注意的是,到目前为止我们发送的所有消息都只有几个字节长。这有几个原因:
- RabbitMQ 所做的许多工作都是按消息进行的,而不是按消息字节进行的。
- 查看大数字总是令人愉快的。
但在现实世界中,我们经常需要发送更大的消息。所以让我们看看下一个图表。
1 -> 1 发送速率消息大小
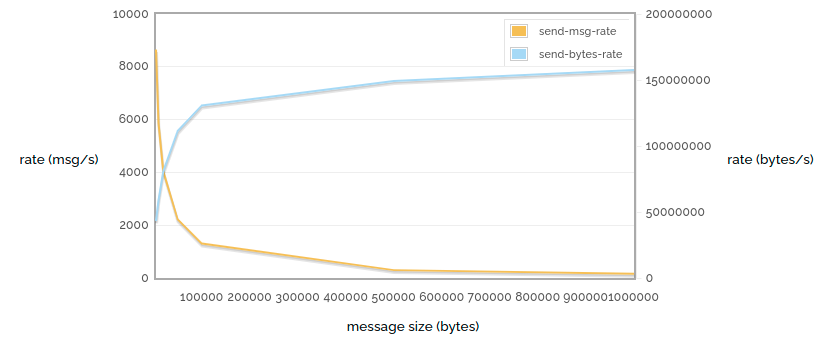
在这里(再次),我们以尽可能快的速度发送未确认/未确认的消息,但这次我们改变了消息的大小。我们可以看到(当然)随着大小的增加,消息速率会进一步下降,但发送的实际字节数会增加,因为我们的路由开销越来越少。
那么消息大小如何影响水平扩展呢?让我们改变不同消息大小的生产者数量。为了改变一下,在这个测试中我们根本没有消费者。
n -> 0 发送消息速率与生产者数量的关系,针对各种消息大小

n -> 0 发送字节速率与生产者数量的关系,针对各种消息大小

在这些测试中,我们可以看到对于小消息,只需要几个生产者就可以达到我们可以发布的上界,但是对于大消息,我们需要更多的生产者来利用可用的带宽。
另一个经常令人困惑的问题是消费者与 prefetch count 相关的性能。RabbitMQ(嗯,AMQP)默认会将所有能发送的消息发送给任何看起来准备好接收它们的消费者。这些未确认消息每个通道的最大数量可以通过设置 prefetch count 来限制。然而,小的 prefetch count 会损害性能(因为我们可能在发送更多消息之前等待 ack 到达)。
所以让我们看看 prefetch count,同时我们也考虑从单个队列中消费的消费者数量。此图包含一些故意荒谬的极端情况。
1 -> n 接收速率与消费者数量 / prefetch count 的关系
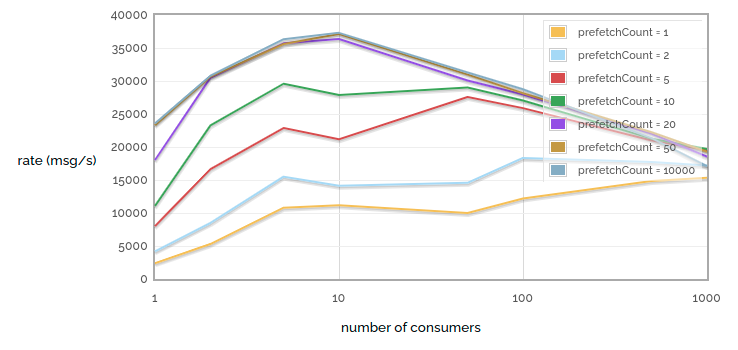
首先要注意的是,极小的 prefetch count 严重影响性能。请注意 prefetch = 1 和 prefetch = 2 之间的巨大性能差异!但我们也遇到了收益递减——请注意,prefetch = 20 和 prefetch = 50 之间的差异很难看清,而 prefetch = 50 和 prefetch = 10000 之间的差异几乎看不见。当然,这是因为对于我们特定的网络链路,prefetch = 50 已经确保我们在等待 ack 时永远不会让消费者饥饿。当然,这个测试是在低延迟链路上运行的——延迟更高的链路将受益于更高的 prefetch count。
其次要注意的是,当我们有少量消费者时,再增加一个会提高性能(我们获得了更多的并行性)。并且在极小的 prefetch count 下,即使增加到大量消费者也有好处(因为每个单独的消费者花费大量时间处于饥饿状态)。但是当我们有较大的 prefetch count 时,增加消费者数量帮助不大,因为即使是少量消费者也可以保持足够忙碌以达到我们队列的最大处理能力,但消费者越多,RabbitMQ 需要做的工作就越多才能跟踪所有这些消费者。
大队列
到目前为止我们看过的所有示例都有一个共同点:实际入队的的消息很少。总的来说,我们看过消息生产速度和消费速度大致相等的场景,因此每个队列的平均长度为 0。
那么当队列变大时会发生什么?当队列很小(或中等)时,它们将完全驻留在内存中。持久化消息也会写入磁盘,但只有在 broker 重启时才会再次读取。
但是当队列变大时,它们会被分页到磁盘,无论是否持久化。在这种情况下,性能可能会受到影响,因为我们突然需要访问磁盘才能将消息发送给消费者。所以让我们做一个测试:向队列发布大量非持久化消息,然后全部消费掉。
队列负载/清空 500k 条消息

在这个小例子中,我们可以看到相当一致的性能:消息很快地进入队列,然后更快地出来。
队列负载/清空 10M 条消息

但是当队列较大时,我们看到性能变化很大。我们看到在加载队列时,最初的吞吐量非常高,然后是暂停,直到队列的一部分被分页到磁盘,然后是更低但更一致的吞吐量。同样,在清空队列时,我们看到从磁盘中拉取消息时的速率要低得多。
磁盘绑定队列的性能是一个复杂的话题——有关更多讨论,请参阅 Matthew 关于此主题的博客文章。
了解更多
- 网络研讨会:RabbitMQ 3.8 有哪些新特性?
- 网络研讨会:使用 RabbitMQ 的开发者应该知道的 10 件事