集群大小调整案例研究 – Quorum 队列 第 1 部分
在本 sizing 系列的第一篇文章中,我们介绍了工作负载、测试以及 AWS ec2 上的集群和存储卷配置。在这篇文章中,我们将使用 quorum 队列进行大小调整分析。我们还对镜像队列进行了大小调整分析。
在这篇文章中,我们将运行强度递增测试,以在理想条件下测量不同发布速率下候选集群的大小。在下一篇文章中,我们将运行弹性测试,以衡量我们的集群是否能够在不利条件下处理目标峰值负载。
所有 quorum 队列都使用以下属性声明
- x-quorum-initial-group-size=3 (复制因子)
- x-max-in-memory-length=0
x-max-in-memory-length 属性强制 quorum 队列在安全的情况下尽快从内存中删除消息体。您可以将其设置为更长的限制,这是最激进的设置 - 旨在避免内存大量增长,但以消费者跟不上时需要进行更多磁盘读取为代价。如果没有此属性,消息体将始终保存在内存中,这可能会导致内存增长到触发内存警报的程度,从而严重影响发布速率 - 这是我们在本工作负载案例研究中希望避免的情况。
理想条件 - 增长强度测试
在之前的文章中,我们讨论了运行基准测试的选项。您可以使用以下命令以这些强度运行此工作负载
bin/runjava com.rabbitmq.perf.PerfTest \
-H amqp://guest:guest@10.0.0.1:5672/%2f,amqp://guest:guest@10.0.0.2:5672/%2f,amqp://guest:guest@10.0.0.3:5672/%2f \
-z 1800 \
-f persistent \
-q 1000 \
-c 1000 \
-ct -1 \
-ad false \
--rate 50 \
--size 1024 \
--queue-pattern 'perf-test-%d' \
--queue-pattern-from 1 \
--queue-pattern-to 100 \
-qa auto-delete=false,durable=false,x-queue-type=quorum \
--producers 200 \
--consumers 200 \
--consumer-latency 10000 \
--producer-random-start-delay 30
只需将 --rate 参数更改为您每次测试需要的速率,并记住它是每个发布者的速率,而不是总组合速率。由于消费者处理时间(消费者延迟)设置为 10 毫秒,我们还需要增加消费者数量以适应更高的发布速率。
请注意,我们设置 durable=false 是因为此属性与 quorum 队列无关。
io1 - 高性能 SSD
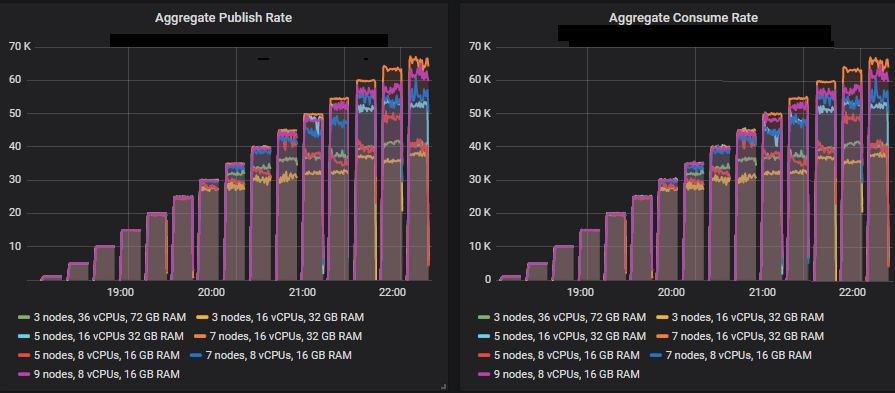
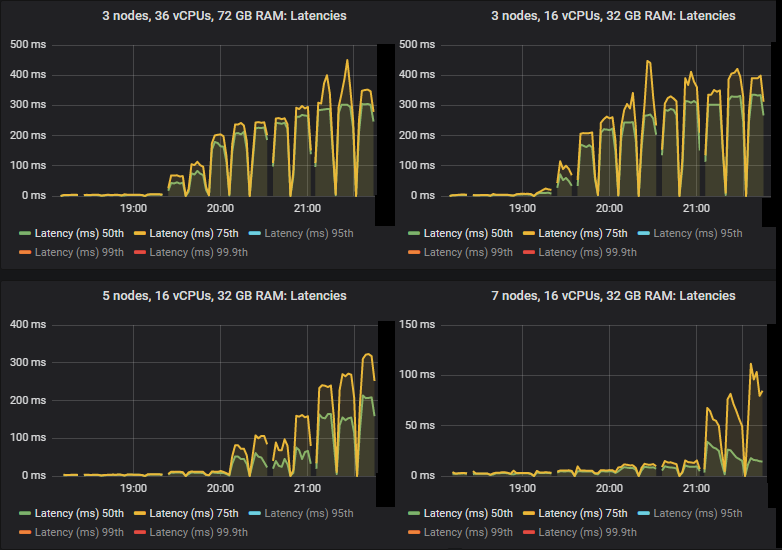
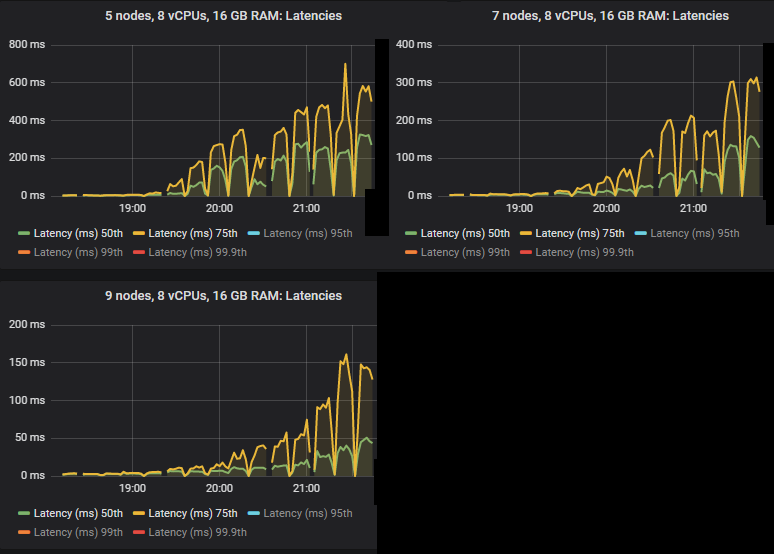
在 quorum 队列达到其限制的强度下,它们倾向于累积消息积压,导致第 95 百分位及以上的端到端延迟升高。以下是第 50 和 75 百分位延迟。
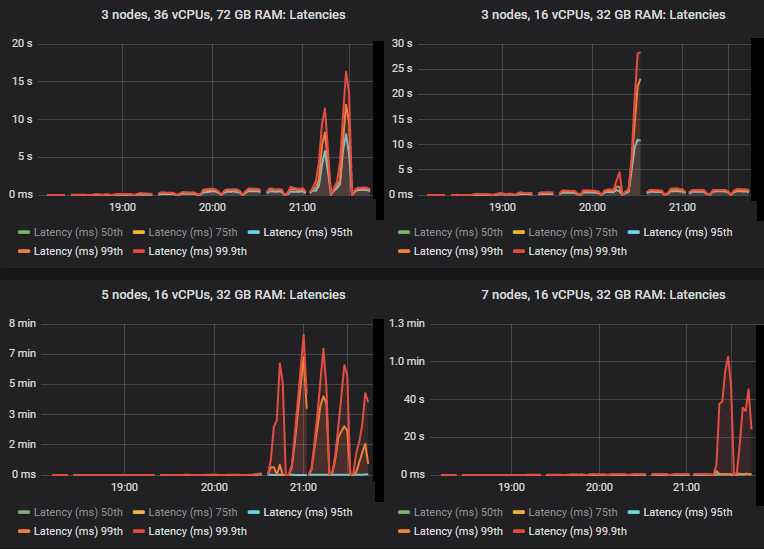
我们看到,在某些情况下,当 quorum 队列达到吞吐量容量时,延迟会急剧升高。
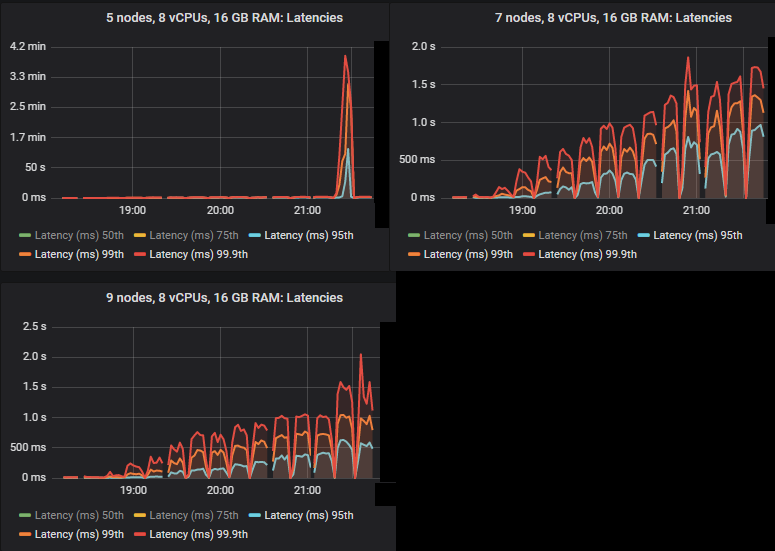
除了 3x16 和 5x8 集群外,所有集群都设法达到了 30k msg/s 的目标峰值,并且所有集群的端到端延迟都低于 1 秒的要求。正如预期的那样,较大的集群实现了最高的吞吐量。
底部吞吐量集群 (3x16) 服务器指标
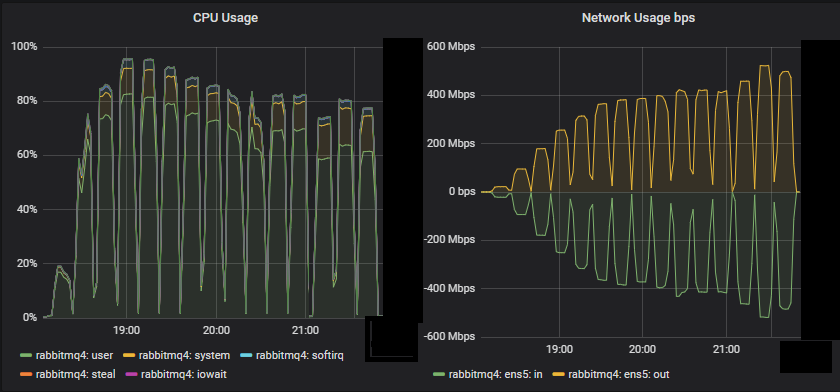
我们看到,对于这个小型集群,CPU 似乎是资源瓶颈。
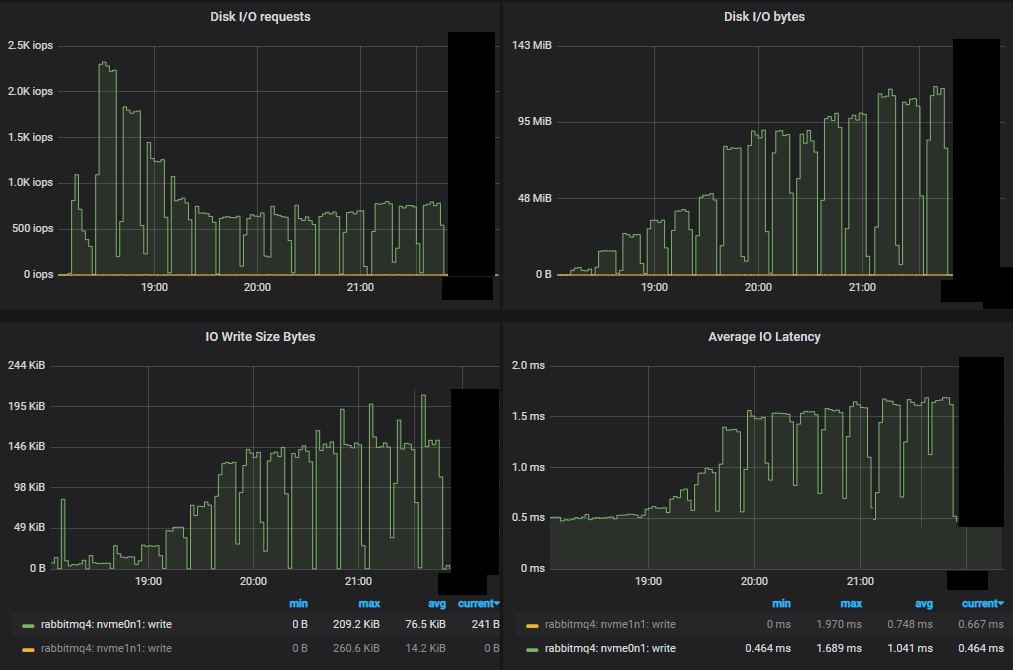
首先,我们看到与镜像队列相比,IOPS 数量低得多。随着我们进行强度递增,IOPS 实际上下降了,每次写入操作变得越来越大。
顶部吞吐量集群服务器指标
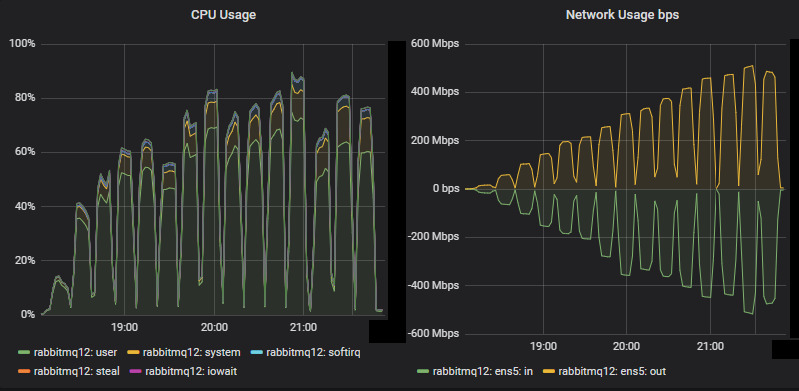
对于这个大型集群,CPU 没有达到饱和。网络带宽达到 500 Mbps,低于镜像队列的相同测试,后者达到 750 Mbps(即使镜像队列的复制因子较低)。之前的博客文章讨论了镜像队列对网络的低效使用。
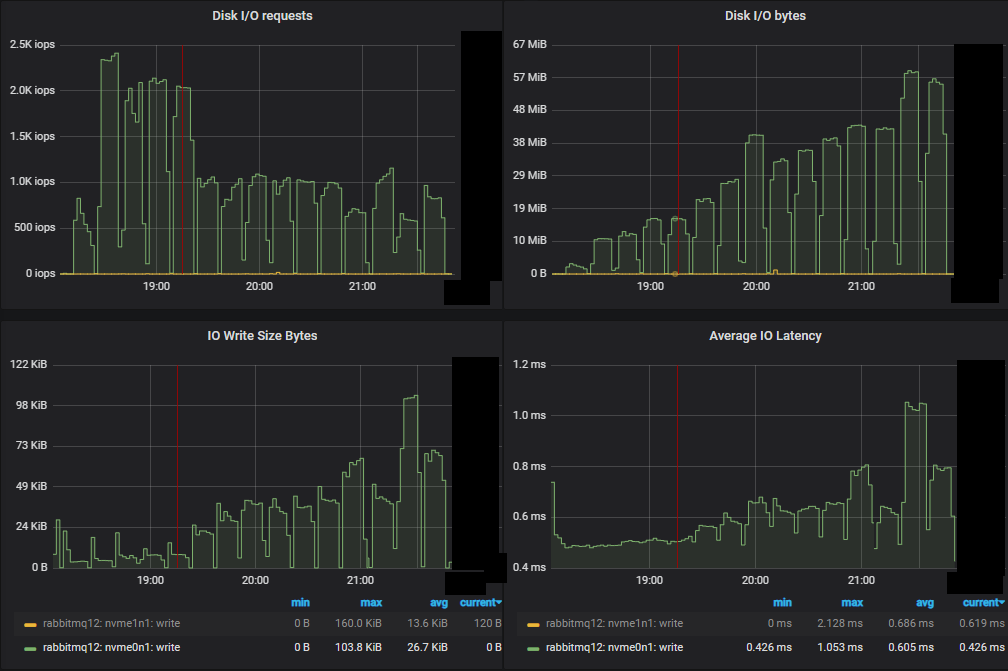
与镜像队列测试一样,性能最差的集群不仅管理了较低的吞吐量,而且磁盘 IO 也更高。这是因为 quorum 队列写入磁盘的方式。每条消息始终写入预写日志 (WAL)。为了控制 WAL 的大小,WAL 文件会被截断,这涉及将其消息写入段文件。有一种优化,如果消息在写入段文件之前被消费者消费和确认,则不会执行第二次磁盘写入 - 就 RabbitMQ 而言,该消息不再存在。这意味着如果消费者跟得上,消息只会写入磁盘一次,但如果消费者落后,则消息最终可能会被写入磁盘两次。
顶部吞吐量集群没有看到资源瓶颈,表明限制是协调成本(基于 Raft 的复制)。
底部吞吐量集群在早期就达到了 90% 以上的 CPU 利用率,这与它停止达到目标吞吐量的那一刻相对应。它在第 4 次测试中达到了 > 90%,并且从第 5 次测试开始,它未能可靠地匹配目标。
因此,quorum 队列将比最多写入磁盘一次的镜像队列使用更多的磁盘带宽。
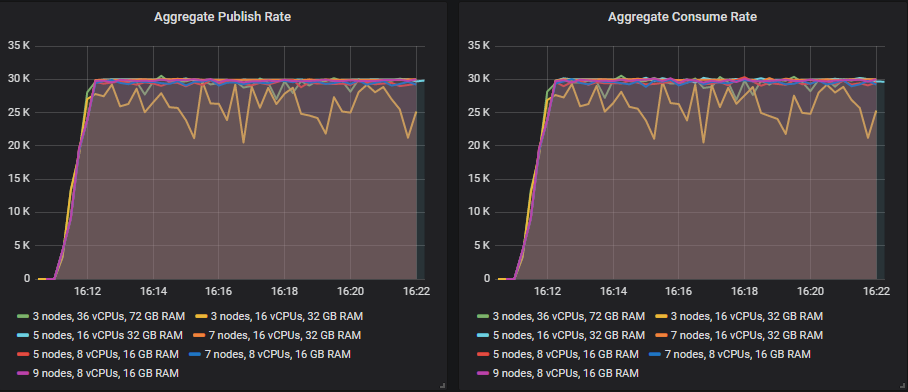
这就是每个集群如何应对 30k msg/s 的目标速率。
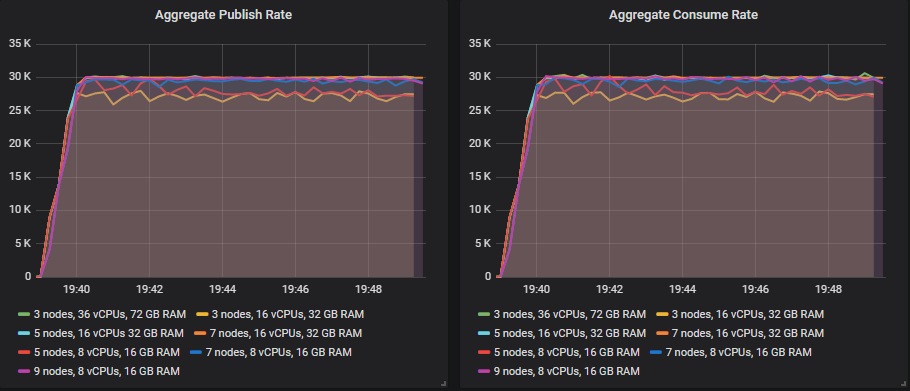
匹配目标吞吐量的排行榜
从 35k msg/s 开始,许多大小继续显示吞吐量随着目标吞吐量的增加而增加,但始终略低于目标。
唯一能够远远超出 30k msg/s 达到目标的尺寸是
- 集群:7 个节点,16 个 vCPU (c5.4xlarge) - 60k msg/s
其余的在每次测试中都低于 35k msg/s 及以上的目标,但仍然显示出更高的吞吐量,因为测试在进行中。这是顶级吞吐量方面的排行榜
- 集群: 7 个节点,16 个 vCPU (c5.4xlarge)。速率: 65k msg/s
- 集群: 9 个节点,8 个 vCPU (c5.2xlarge)。速率: 63k msg/s
- 集群: 7 个节点,8 个 vCPU (c5.2xlarge)。速率: 54k msg/s
- 集群: 5 个节点,16 个 vCPU (c5.4xlarge)。速率: 53k msg/s
- 集群: 5 个节点,8 个 vCPU (c5.2xlarge)。速率: 50k msg/s
- 集群: 3 个节点,36 个 vCPU (c5.9xlarge)。速率: 40k msg/s
- 集群: 3 个节点,16 个 vCPU (c5.4xlarge)。速率: 37k msg/s
横向扩展以及向上/向外扩展的中间地带显示了最佳结果。
在顶级吞吐量下,每 1000 条消息每月的成本排行榜。
- 集群: 5 个节点,8 个 vCPU (c5.2xlarge)。成本: $97 (50k)
- 集群: 3 个节点,16 个 vCPU (c5.4xlarge. 成本: $98 (37k)
- 集群: 5 个节点,16 个 vCPU (c5.4xlarge. 成本: $115 (53k)
- 集群: 7 个节点,8 个 vCPU (c5.2xlarge. 成本: $126 (54k)
- 集群: 3 个节点,36 个 vCPU (c5.9xlarge. 成本: $137 (40k)
- 集群: 9 个节点,8 个 vCPU (c5.2xlarge. 成本: $139 (63k)
- 集群: 7 个节点,16 个 vCPU (c5.4xlarge. 成本: $142 (65k)
在 30k msg/s 目标下,每 1000 条消息每月的成本排行榜。
我们看到有两个集群没有完全达到 30k msg/s 的目标。达到目标的集群的排行榜
- 集群: 5 个节点,16 个 vCPU (c5.4xlarge)。成本: $135
- 集群: 7 个节点,8 个 vCPU (c5.2xlarge)。成本: $151
- 集群: 3 个节点,36 个 vCPU (c5.9xlarge)。成本: $183
- 集群: 9 个节点,8 个 vCPU (c5.2xlarge)。成本: $194
- 集群: 7 个节点,16 个 vCPU (c5.4xlarge)。成本: $204
成本效益和性能在本测试中彼此冲突。当存储卷是最昂贵的项目时,横向扩展是昂贵的。最佳价值来自横向扩展和向上扩展的中间地带。
我们真的需要那些昂贵的 io1 固态硬盘吗?本测试中的 IOPS 相对较低,我们没有超过 250MiB/s,因此便宜的 gp2 卷应该是好的选择。让我们看看。
gp2 - 通用型 SSD
和以前一样,第 50 和 75 百分位数仍然非常低。
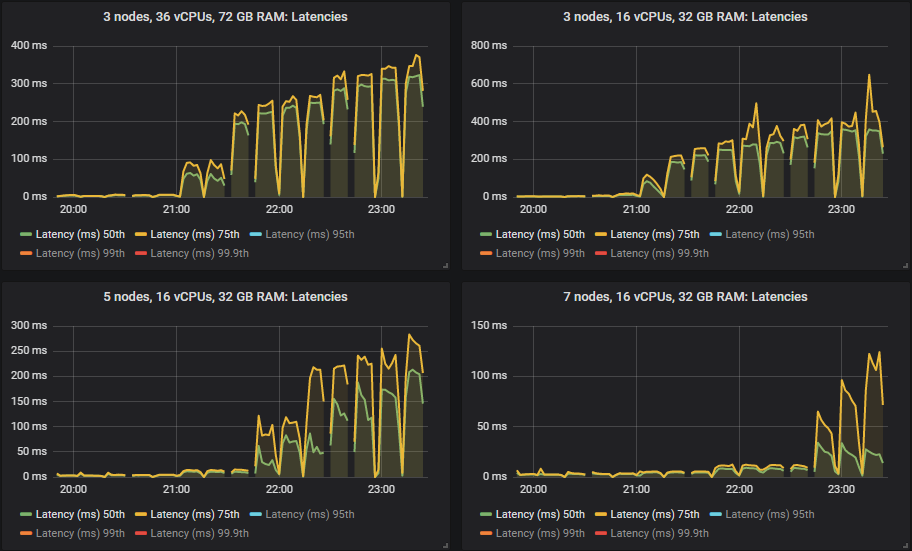
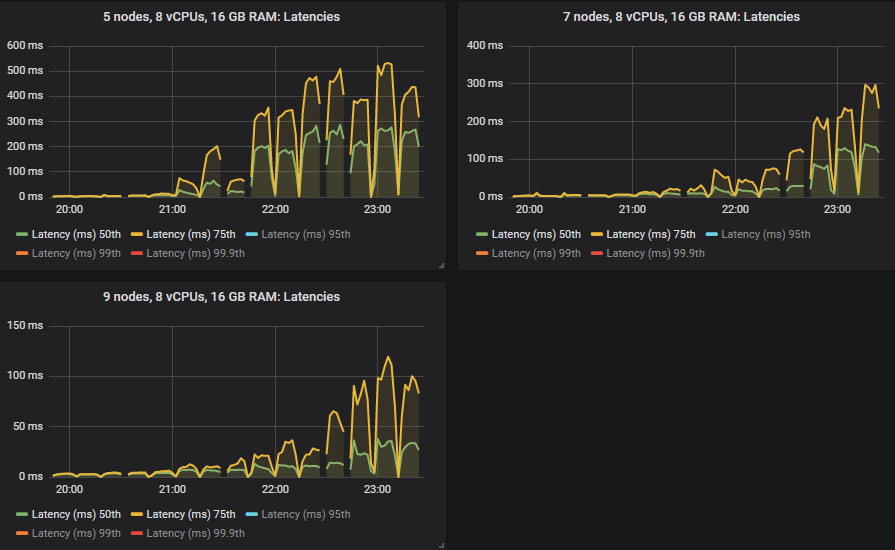
但是,当集群达到其吞吐量容量时,第 95、99 和 99.9 百分位数在某些情况下会急剧升高。这种延迟基本上意味着队列开始累积消息。这些积压只发生在较大的 16 vCPU 集群上。
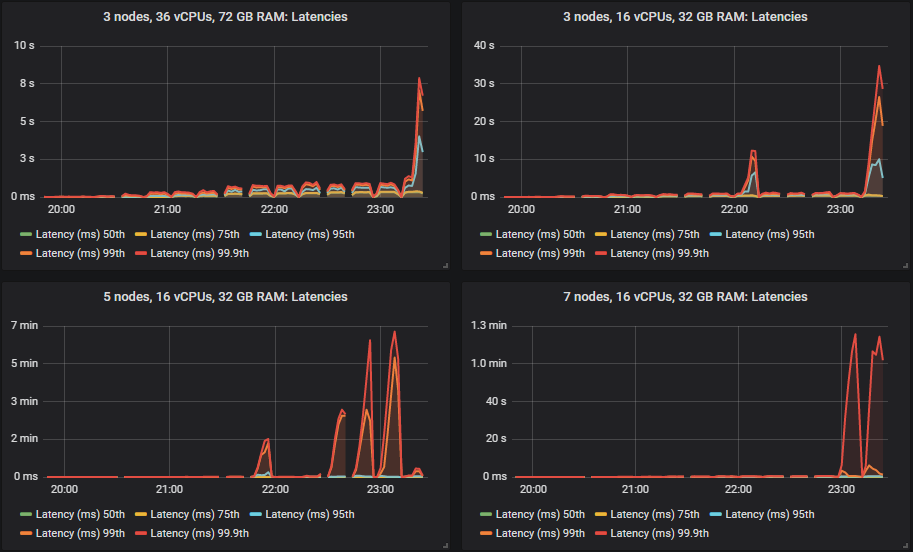
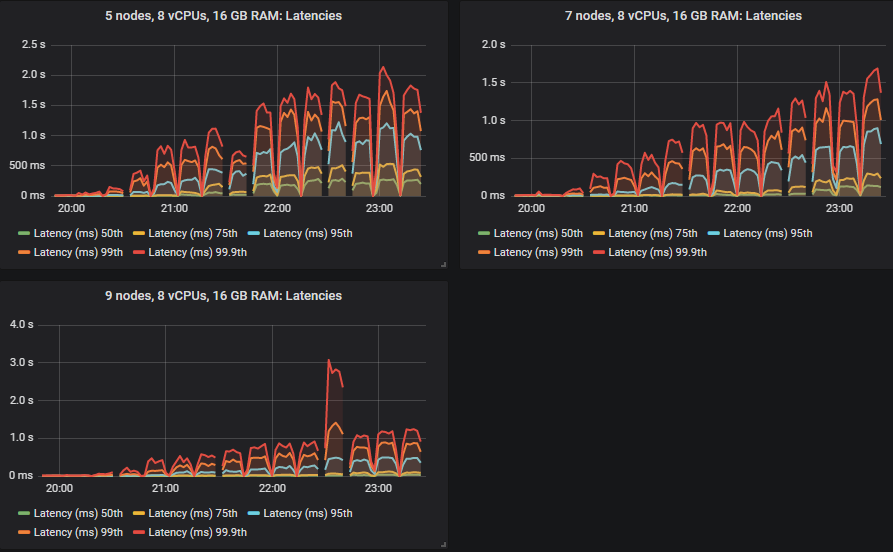
gp2 卷的结果不比更昂贵的 io1 卷差。
底部吞吐量集群 (3x16) 磁盘指标
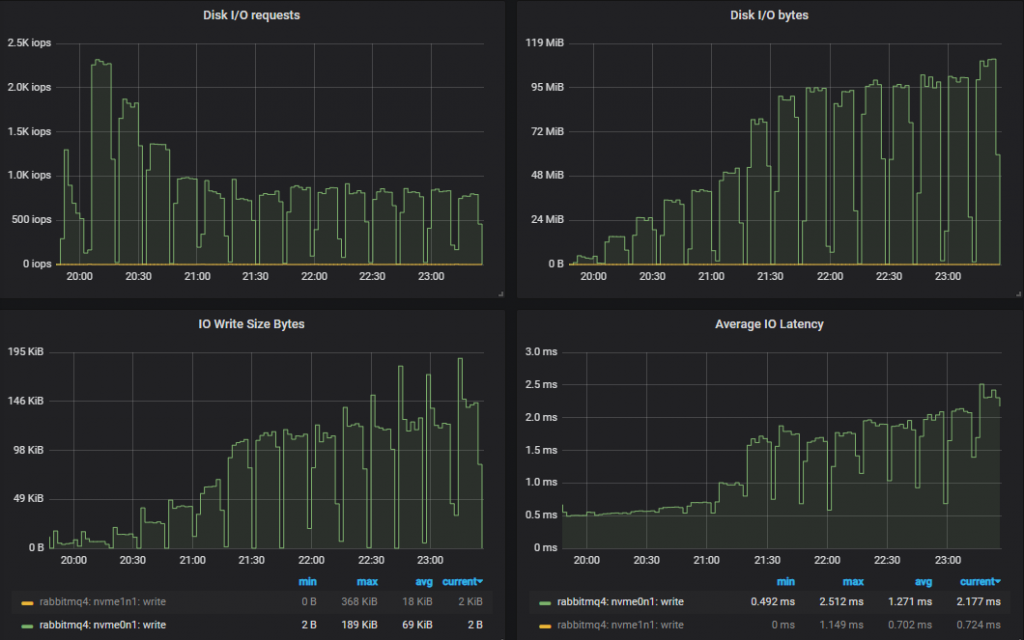
顶部吞吐量集群 (7x16) 磁盘指标。
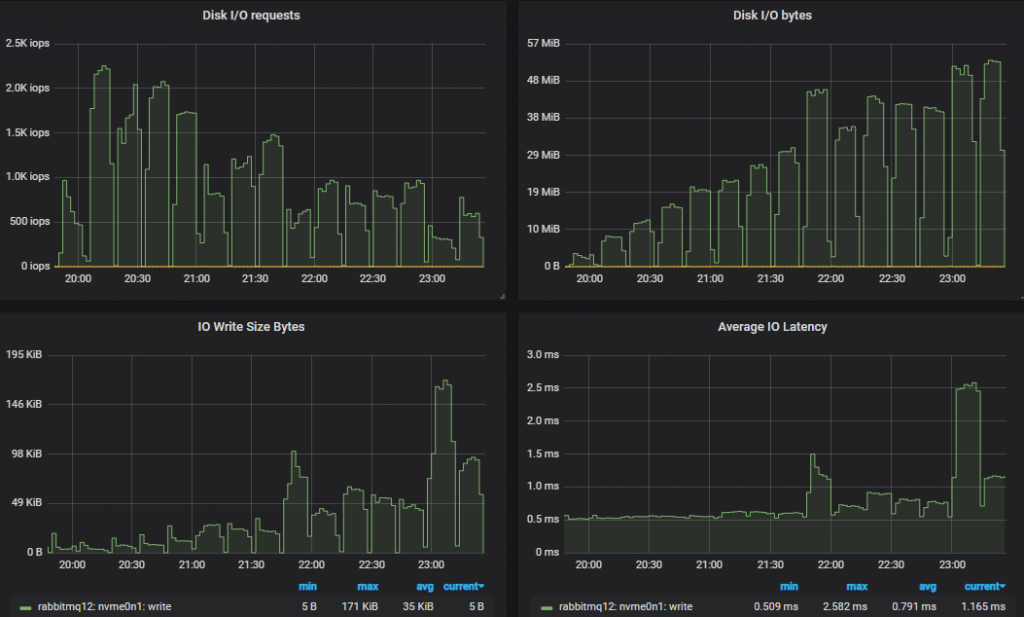
在这两种情况下,IOPS 开始时都很高,相对接近 3000 IOPS 限制(达到 2.3k),但随着负载增加,IO 大小变得更大,操作次数减少。
在 30k msg/s 目标和 1kb 消息的情况下,即使我们每条消息写入两次,我们仍然不会达到 gp2 的 250MiB/s 限制。和以前一样,较小的集群看到更多的磁盘 IO,因为它比更大、性能更高的集群执行了更多的双重写入。
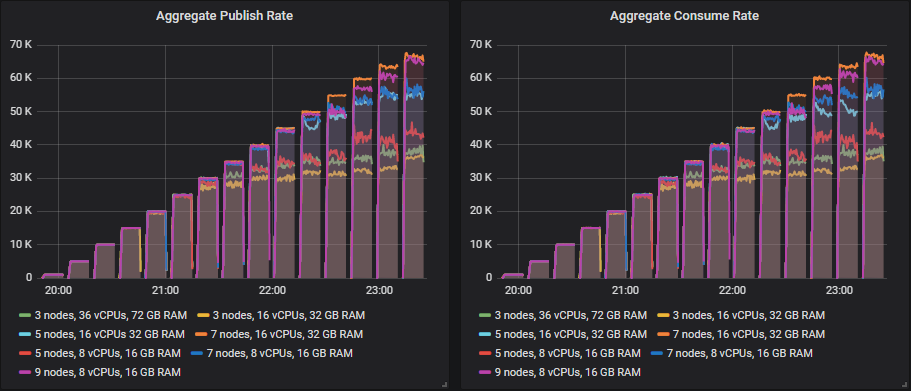
这是 30k msg/s 目标的结果。
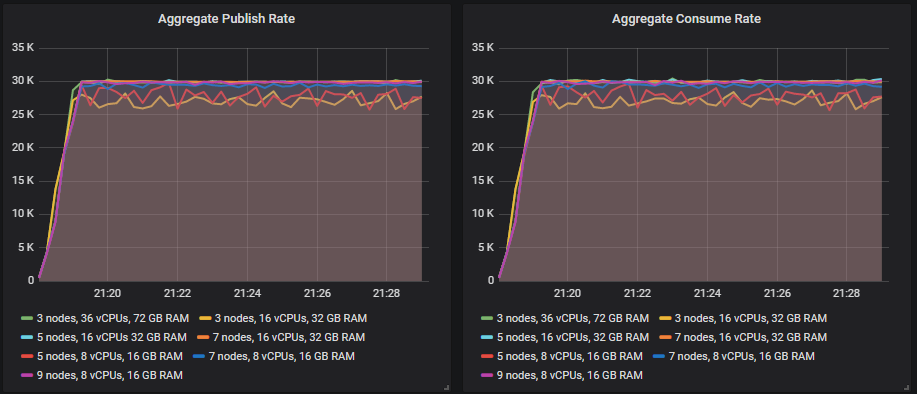
匹配目标吞吐量的排行榜
从 35k msg/s 及以上,许多尺寸继续显示吞吐量随着目标吞吐量的增加而增加,但始终略低于目标。
能够远远超出该目标达到目标的尺寸是
- 集群:7 个节点,c5.4xlarge - 60k msg/s
在超过 35k msg/s 的测试中,其余的都低于目标,要么只差一点,要么差一些幅度,但仍然显示出更高的吞吐量,因为测试在进行中。这是顶级吞吐量方面的排行榜
- 集群: 7 个节点,16 个 vCPU (c5.4xlarge)。速率: 67k msg/s
- 集群: 9 个节点,8 个 vCPU (c5.2xlarge)。速率: 66k msg/s
- 集群: 5 个节点,16 个 vCPU (c5.4xlarge)。速率: 54k msg/s
- 集群: 7 个节点,8 个 vCPU (c5.2xlarge)。速率: 54k msg/s
- 集群: 5 个节点,8 个 vCPU (c5.2xlarge)。速率: 42k msg/s
- 集群: 3 个节点,36 个 vCPU (c5.9xlarge)。速率: 37k msg/s
- 集群: 3 个节点,16 个 vCPU (c5.4xlarge)。速率: 36k msg/s
横向扩展以及向上/向外扩展的中间地带显示了最佳结果。
在顶级吞吐量下,每 1000 条消息每月的成本排行榜。
- 集群: 5 个节点,8 个 vCPU (c5.2xlarge)。成本: $41 (42k)
- 集群: 7 个节点,8 个 vCPU (c5.2xlarge)。成本: $45 (54k)
- 集群: 9 个节点,8 个 vCPU (c5.2xlarge)。成本: $47 (66k)
- 集群: 3 个节点,16 个 vCPU (c5.4xlarge)。成本: $49 (36k)
- 集群: 5 个节点,16 个 vCPU (c5.4xlarge)。成本: $55 (54k)
- 集群: 7 个节点,16 个 vCPU (c5.4xlarge)。成本: $72 (67k)
- 集群: 3 个节点,36 个 vCPU (c5.9xlarge)。成本: $97 (37k)
在 30k msg/s 目标下,每 1000 条消息每月的成本排行榜。
达到 30k msg/s 目标的集群
- 集群: 7 个节点,8 个 vCPU (c5.2xlarge)。成本: $54
- 集群: 9 个节点,8 个 vCPU (c5.2xlarge)。成本: $69
- 集群: 5 个节点,16 个 vCPU (c5.4xlarge)。成本: $98
- 集群: 7 个节点,16 个 vCPU (c5.4xlarge)。成本: $107
- 集群: 3 个节点,36 个 vCPU (c5.9xlarge)。成本: $120
成本效益和性能在本测试中更加一致。小型横向扩展虚拟机由于其廉价的存储卷而显示出极高的投资回报率。对于此工作负载,io1 根本不值得。
在之前的文章中,我们建议对 quorum 队列使用 SSD。我们表明,quorum 队列在纯 quorum 队列工作负载下在 HDD 上表现良好。但是,当您运行经典队列和 quorum 队列的混合工作负载时,我们发现 HDD 无法提供 quorum 队列所需的性能。鉴于这是一个纯粹的 quorum 工作负载,让我们看看它们在 HDD 上的表现如何。
st1 - HDD
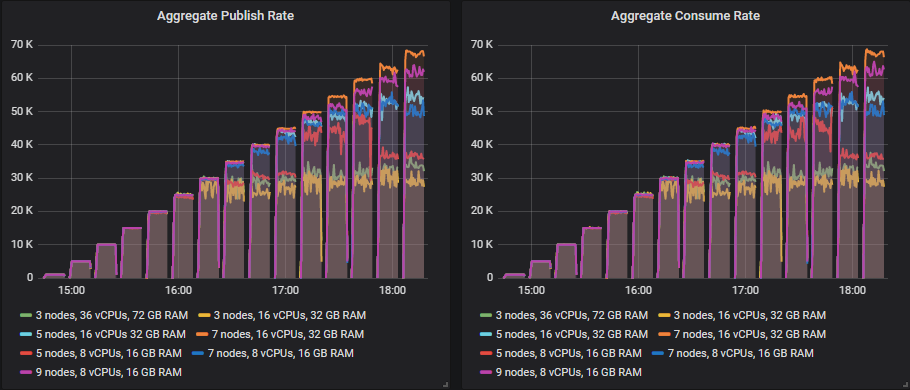
quorum 队列在 HDD 上表现良好,尽管一旦集群达到其吞吐量容量,吞吐量就会变得更加不稳定。除了在这些测试中始终名列前茅的 7x16 集群外,所有集群的吞吐量也略低。我们通常建议使用 SSD,因为由于经典队列的随机 IO 特性,混合经典/quorum 队列工作负载的性能可能会显着下降。但此测试表明,对于纯 quorum 队列工作负载,HDD 可以表现良好。
第 50 和 75 百分位延迟高于 SSD,但除了在更高强度下看到消息积压的 5x8 集群外,所有延迟都低于 1 秒。
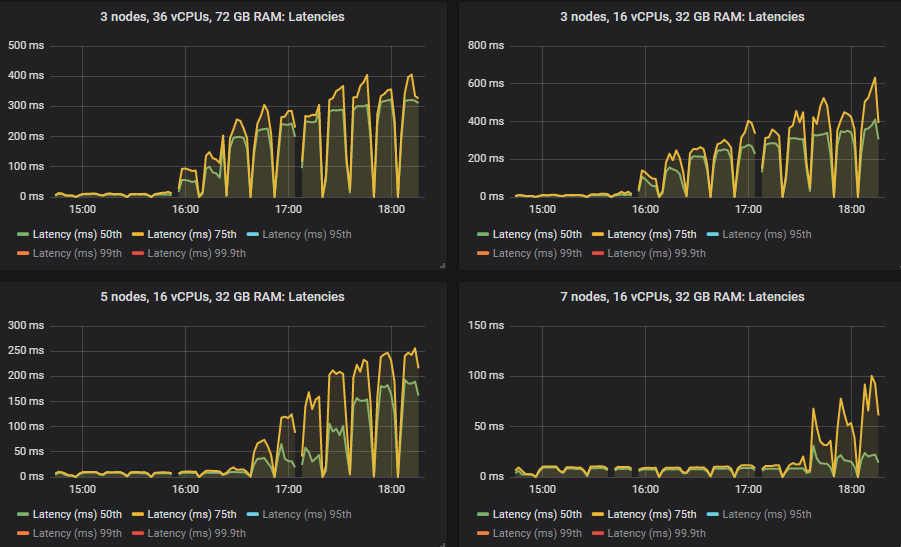
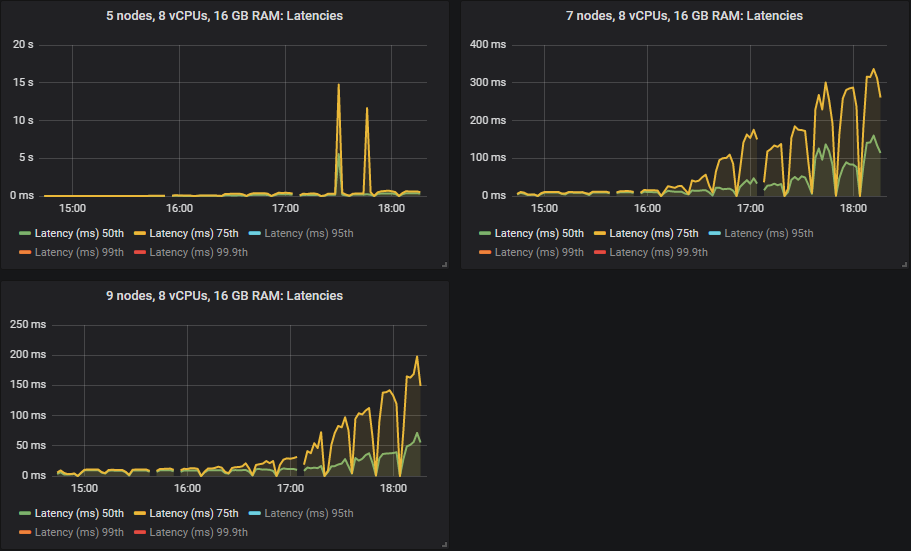
与 SSD 一样,在某些情况下,当集群达到其吞吐量容量时,延迟会急剧升高(这意味着发生了少量消息积压)。
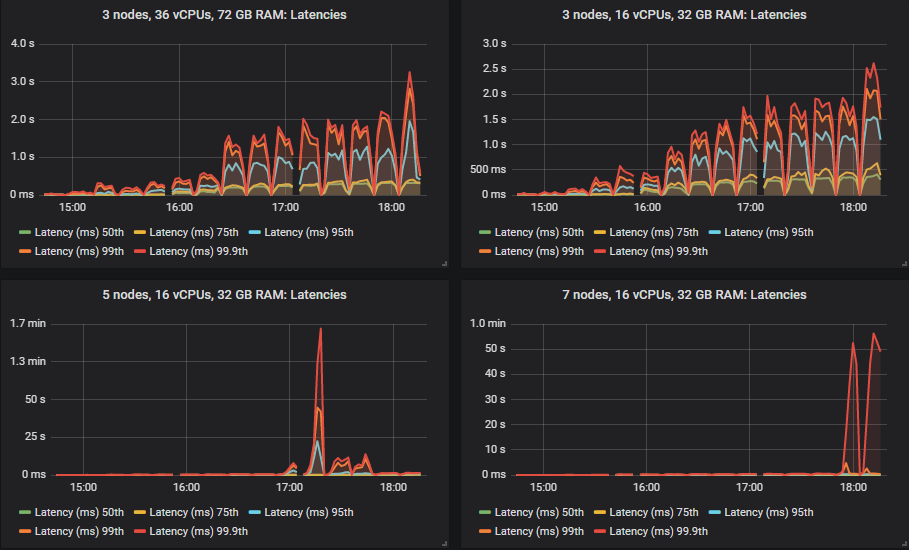
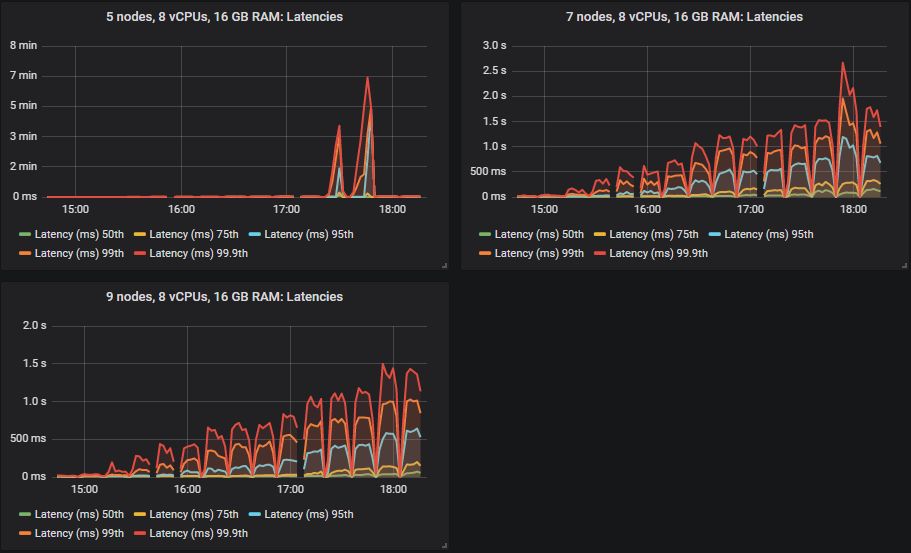
重要的是,在 30k msg/s 目标下,所有延迟都低于 1 秒。
查看磁盘指标,正如对 HDD 的预期,IOPS 通常再次较低,并且写入大小相应较大。
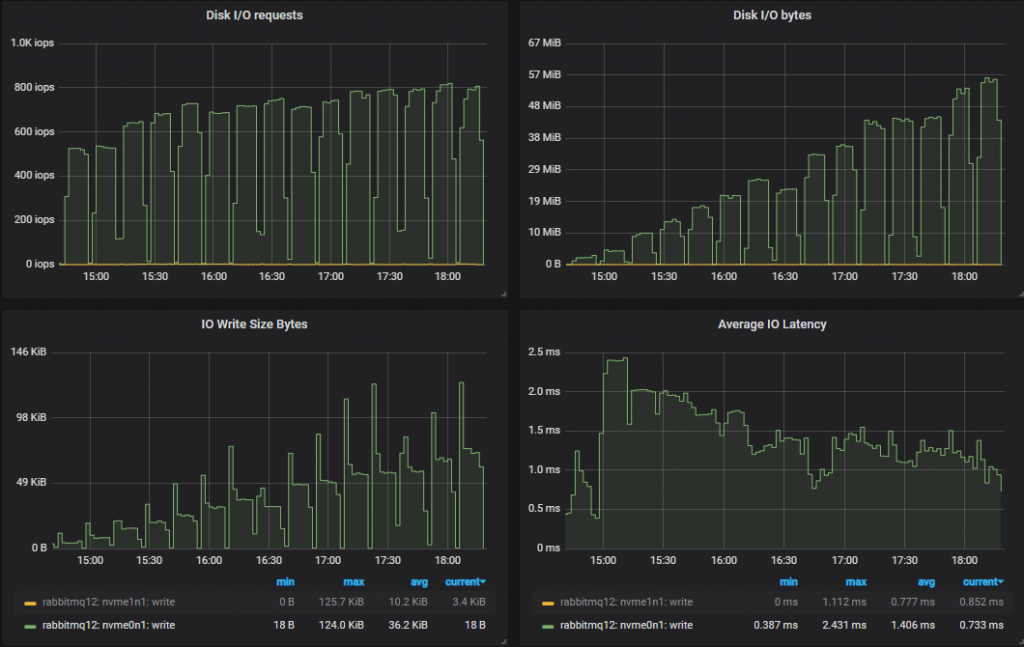
这是 30k msg/s 目标的结果。
这次我们可以说 5x8 集群已达到 30k msg/s 目标,而当使用 SSD 时,它没有达到该目标。
从 35k msg/s 及以上,许多尺寸继续显示吞吐量随着目标吞吐量的增加而增加,但略低于目标。
能够超出该目标达到目标的尺寸是
- 集群:7 个节点,16 个 vCPU (c5.4xlarge)。速率: 60k msg/s
- 集群: 9 个节点,8 个 vCPU (c5.2xlarge)。速率: 40k msg/s
其余的在每次测试中都低于 35k msg/s 以上的目标,但仍然显示出更高的吞吐量,因为测试在进行中。这是顶级吞吐量方面的排行榜
- 集群: 7 个节点,16 个 vCPU (c5.4xlarge)。速率: 67k msg/s
- 集群: 9 个节点,8 个 vCPU (c5.2xlarge)。速率: 62k msg/s
- 集群: 5 个节点,16 个 vCPU (c5.4xlarge)。速率: 54k msg/s
- 集群: 7 个节点,8 个 vCPU (c5.2xlarge)。速率: 50k msg/s
- 集群: 5 个节点,8 个 vCPU (c5.2xlarge)。速率: 37k msg/s
- 集群: 3 个节点,36 个 vCPU (c5.9xlarge)。速率: 32k msg/s
- 集群: 3 个节点,16 个 vCPU (c5.4xlarge)。速率: 27k msg/s
横向扩展以及向上/向外扩展的中间地带显示了最佳结果。
在顶级吞吐量下,每 1000 条消息每月的成本排行榜。
- 集群: 5 个节点,16 个 vCPU (c5.4xlarge)。成本: $74 (54k)
- 集群: 5 个节点,8 个 vCPU (c5.2xlarge)。 成本: $76 (37k)
- 集群: 7 个节点,8 个 vCPU (c5.2xlarge)。 成本: $78 (50k)
- 集群: 9 个节点,8 个 vCPU (c5.2xlarge)。 成本: $81 (62k)
- 集群: 3 个节点,16 个 vCPU (c5.4xlarge)。 成本: $89 (27k)
- 集群: 7 个节点,16 个 vCPU (c5.4xlarge)。 成本: $94 (67k)
- 集群: 3 个节点,36 个 vCPU (c5.9xlarge)。 成本: $132 (32k)
在 30k msg/s 目标下,每 1000 条消息每月的成本排行榜。
- 集群: 5 个节点,8 个 vCPU (c5.2xlarge)。 成本: $93
- 集群: 7 个节点,8 个 vCPU (c5.2xlarge)。 成本: $131
- 集群: 5 个节点,16 个 vCPU (c5.4xlarge)。 成本: $134
- 集群: 3 个节点,36 个 vCPU (c5.9xlarge)。 成本: $142
- 集群: 9 个节点,8 个 vCPU (c5.2xlarge)。 成本: $168
- 集群: 7 个节点,16 个 vCPU (c5.4xlarge)。 成本: $211
成本效益和性能在这种情况下并非彼此冲突(如 io1),但它们也没有对齐(如 gp2)。横向扩展最适合性能,但更昂贵的卷意味着横向扩展现在也不是最具成本效益的。中间地带以及横向扩展和向上扩展是最佳选择。
端到端延迟和三种卷类型
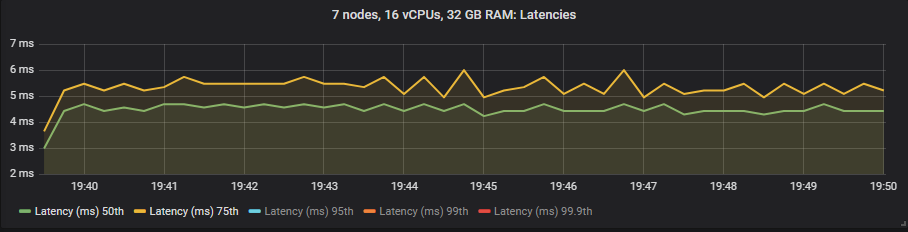
在这些测试中,我们将端到端延迟视为消息发布和消费之间的时间。如果我们查看 30k msg/s 的目标速率和 7x16 集群类型,我们会看到
io1 SSD
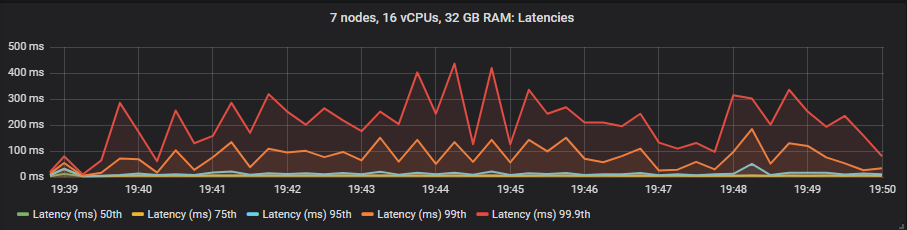
gp2 SSD
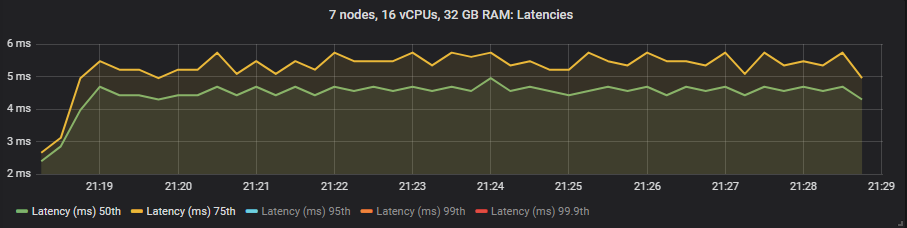
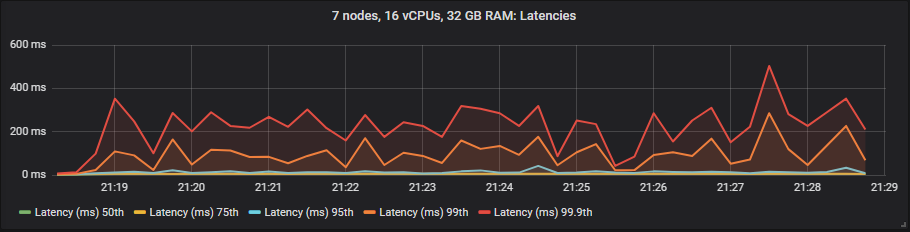
st1 HDD
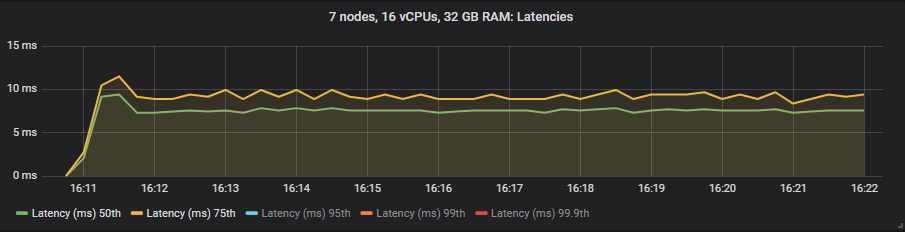
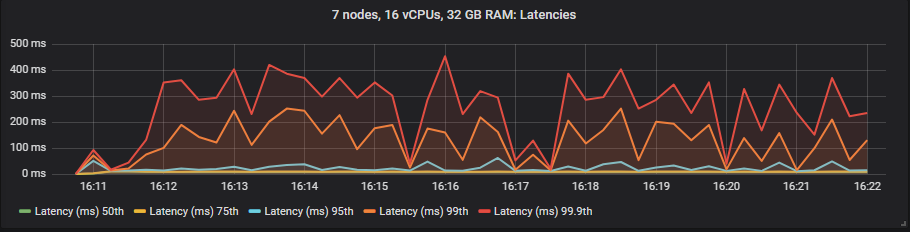
与镜像队列不同,我们没有看到使用昂贵的 io1 卷相比 gp2 在延迟方面有任何好处。如预期的那样,HDD 显示的端到端延迟高于 SSD。
强度递增基准测试 - 结论
到目前为止,结论是
- 昂贵的 io1 卷根本不值得。它的性能不比 gp2 好。但是,如果我们有更大的工作负载或更大的消息,我们可能需要一个能够超过 250MiB/s 的卷,在这些情况下,我们可能会选择 io1,但不是使用高 IOPS。使用 io1,您需要按 GB 支付卷的费用,还需要支付 IOPS 的费用。因此,支付 3000(或更少)而不是 10000 是有意义的。
- 廉价的 gp2 卷提供了性能和成本的最佳组合,并且是大多数工作负载的最佳选择。请记住,我们使用了 1TB 大小,它没有突发 IOPS,并且有 250 MiBs 的限制(我们从未达到)。
- 使用廉价的存储卷,横向扩展较小的 8 vCPU 虚拟机是最具成本效益的,并且在性能方面也是最佳的。
- 对于昂贵的卷,采用横向扩展和向上扩展的中间地带最具成本效益。
- 使用 3 个大型虚拟机进行向上扩展从来都不是最佳选择。
30k msg/s 吞吐量下,每 1000 条消息每月成本的前 5 名配置
- 集群: 7 个节点,8 个 vCPU (c5.2xlarge),gp2 SDD。成本: $54
- 集群: 9 个节点,8 个 vCPU (c5.2xlarge),gp2 SDD。成本: $69
- 集群: 5 个节点,8 个 vCPU (c5.2xlarge),st1 HDD。 成本: $93
- 集群: 5 个节点,16 个 vCPU (c5.4xlarge),gp2 SDD。成本: $98
- 集群: 7 个节点,16 个 vCPU (c5.4xlarge),gp2 SDD。成本: $107
我们只在理想条件下进行了测试...
我们从 21 种不同的集群配置和 15 种不同的工作负载强度中收集了大量数据。我们认为到目前为止,我们应该选择使用廉价 gp2 卷的中型到大型小型虚拟机集群。但这测试的是队列为空或接近为空的理想情况,在这种情况下,RabbitMQ 以其峰值性能运行。接下来,我们将运行更多测试,以确保尽管 Broker 丢失且队列积压发生,我们选择的集群大小仍然能够提供我们需要的性能。接下来我们测试弹性。