RabbitMQ 出现问题时通知我

如果您希望在您的 RabbitMQ 部署出现问题时收到通知,现在您可以设置我们在 RabbitMQ Cluster Operator 仓库中提供的 RabbitMQ 监控和警报。我们没有要求您按照一系列步骤来设置 RabbitMQ 监控和警报,而是将它们合并到了一个命令中。虽然这是一个 Kubernetes 特定的快速入门,并且您可以在 Kubernetes 之外使用这些 Prometheus 警报,但设置将需要您更多的考虑和努力。我们分享快速简便的方法,开源且对所有人免费。
当一切都设置好并且 RabbitMQ 出现问题时,这是一个您可以预期的通知示例
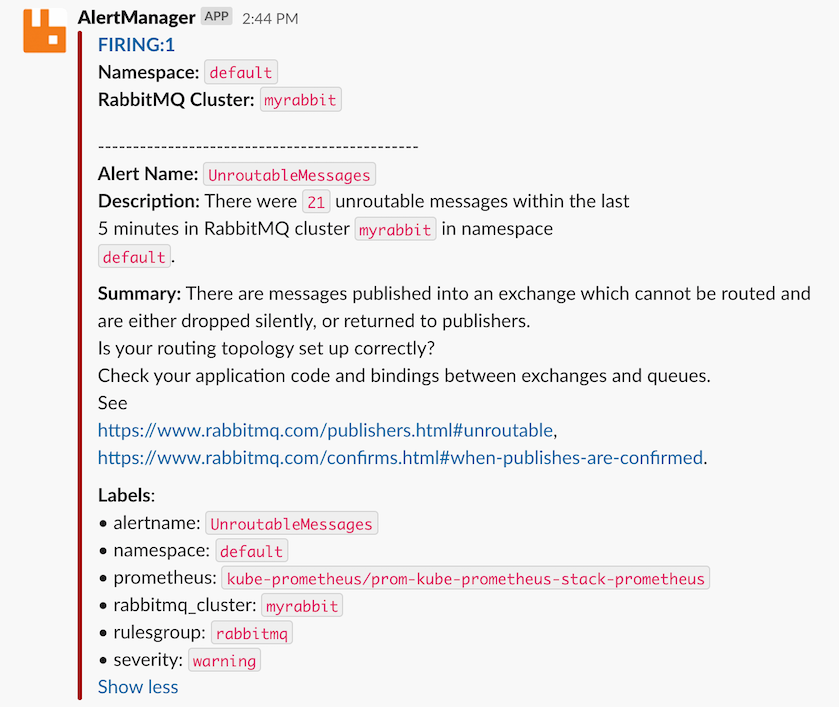
上面是一个很好的例子,说明了问题发生时可能不明显,并且需要几个步骤进行故障排除。此通知清楚地表明何时传入的消息未在 RabbitMQ 中路由,而不是由于配置错误而丢失消息。
今天有哪些警报可用?
- NoMajorityOfNodesReady:只有少数 RabbitMQ 节点可以为客户端提供服务。某些队列可能不可用,包括复制的队列。
- PersistentVolumeMissing:RabbitMQ 节点缺少用于持久化数据的卷,无法启动。这可能是配置错误或容量问题。
- InsufficientEstablishedErlangDistributionLinks:由于网络问题或不正确的权限,RabbitMQ 节点未进行集群。
- UnroutableMessages:消息未从通道路由到队列。需要审查路由拓扑。
- HighConnectionChurn:客户端过于频繁地打开和关闭连接,这是一种反模式。客户端应使用长连接。
- LowDiskWatermarkPredicted:预计可用磁盘空间将在 24 小时内耗尽。限制队列积压、加快消费速度或增加磁盘大小。
- FileDescriptorsNearLimit:80% 的可用文件描述符正在使用中。减少连接数、减少持久队列或提高文件描述符限制将有所帮助。
- TCPSocketsNearLimit:80% 的可用 TCP 套接字正在使用中。更多通道、更少连接或更均匀地分布在集群中将有所帮助。
- ContainerRestarts:运行 RabbitMQ 的 Erlang VM 系统进程异常退出。最常见的原因是配置错误。
- RabbitMQClusterOperatorUnavailableReplicas:管理 RabbitMQ 集群的 Operator 不可用。Pod 调度或配置错误问题。
如何快速开始?
您将需要以下内容
现在您可以准备在终端中运行以下命令
git clone https://github.com/rabbitmq/cluster-operator.git
# Optionally, set the name of the Slack channel and the Slack Webhook URL
# If you don't have a Slack Webhook URL, create one via https://api.slack.com/messaging/webhooks
# export SLACK_CHANNEL='#my-channel'
# export SLACK_API_URL='https://hooks.slack.com/services/paste/your/token'
./cluster-operator/observability/quickstart.sh
最后一个命令大约需要 5 分钟,它会设置整个 Kubernetes 上的 RabbitMQ 堆栈
- RabbitMQ Cluster Operator 将
RabbitmqCluster声明为自定义资源定义 (CRD),并管理 Kubernetes 中的所有 RabbitMQ 集群 - kube-prometheus-stack Helm chart,它安装了
- Prometheus Operator 管理 Prometheus 和 Alertmanager,添加了
PrometheusRule和ServiceMonitor自定义资源定义 - Prometheus 从所有 RabbitMQ 节点抓取(即读取)指标,将指标存储在时间序列数据库中,评估警报规则
- Alertmanager 接收来自 Prometheus 的警报,按 RabbitMQ 集群对其进行分组,可选择将通知发送到 Slack(或其他服务)
- Grafana 可视化来自 Prometheus 的指标
- kube-state-metrics 提供 RabbitMQ 警报规则依赖的 Kubernetes 指标
- Prometheus Operator 管理 Prometheus 和 Alertmanager,添加了
- ServiceMonitor Prometheus 的配置,它有助于从所有 RabbitMQ 节点发现 RabbitMQ 指标
- PrometheusRule 用于每个 RabbitMQ Prometheus 警报条件
- Secret 用于 Alertmanager Slack 配置(可选)
- ConfigMap 用于每个 RabbitMQ Grafana 仪表板定义
触发您的第一个 RabbitMQ 警报
要触发警报,我们需要一个 RabbitMQ 集群。这是创建集群的最简单方法
# Add kubectl-rabbitmq plugin to PATH so that it can be used directly
export PATH="$PWD/cluster-operator/bin:$PATH"
# Use kubectl-rabbitmq plugin to create RabbitmqClusters via kubectl
kubectl rabbitmq create myrabbit --replicas 3
要触发 NoMajorityOfNodesReady 警报,我们停止三个节点中的两个节点上的 rabbit 应用程序
kubectl exec myrabbit-server-0 --container rabbitmq -- rabbitmqctl stop_app
kubectl exec myrabbit-server-1 --container rabbitmq -- rabbitmqctl stop_app
在 2 分钟内,三个 RabbitMQ 节点中的两个将显示为未 READY
kubectl rabbitmq get myrabbit
NAME READY STATUS RESTARTS AGE
- pod/myrabbit-server-0 1/1 Running 0 70s
+ pod/myrabbit-server-0 0/1 Running 0 3m
- pod/myrabbit-server-1 1/1 Running 0 70s
+ pod/myrabbit-server-1 0/1 Running 0 3m
pod/myrabbit-server-2 1/1 Running 0 3m
Pod 仍然在 Running 状态,因为 rabbitmqctl stop_app 命令使 Erlang VM 系统进程保持运行。
要查看在 Prometheus 中触发的 NoMajorityOfNodesReady 警报,我们在浏览器中打开 Prometheus UI:https://:9090/alerts。为了使其工作,我们将本地端口 9090 转发到 Kubernetes 内部运行的 Prometheus 端口 9090
kubectl -n kube-prometheus port-forward svc/prom-kube-prometheus-stack-prometheus 9090
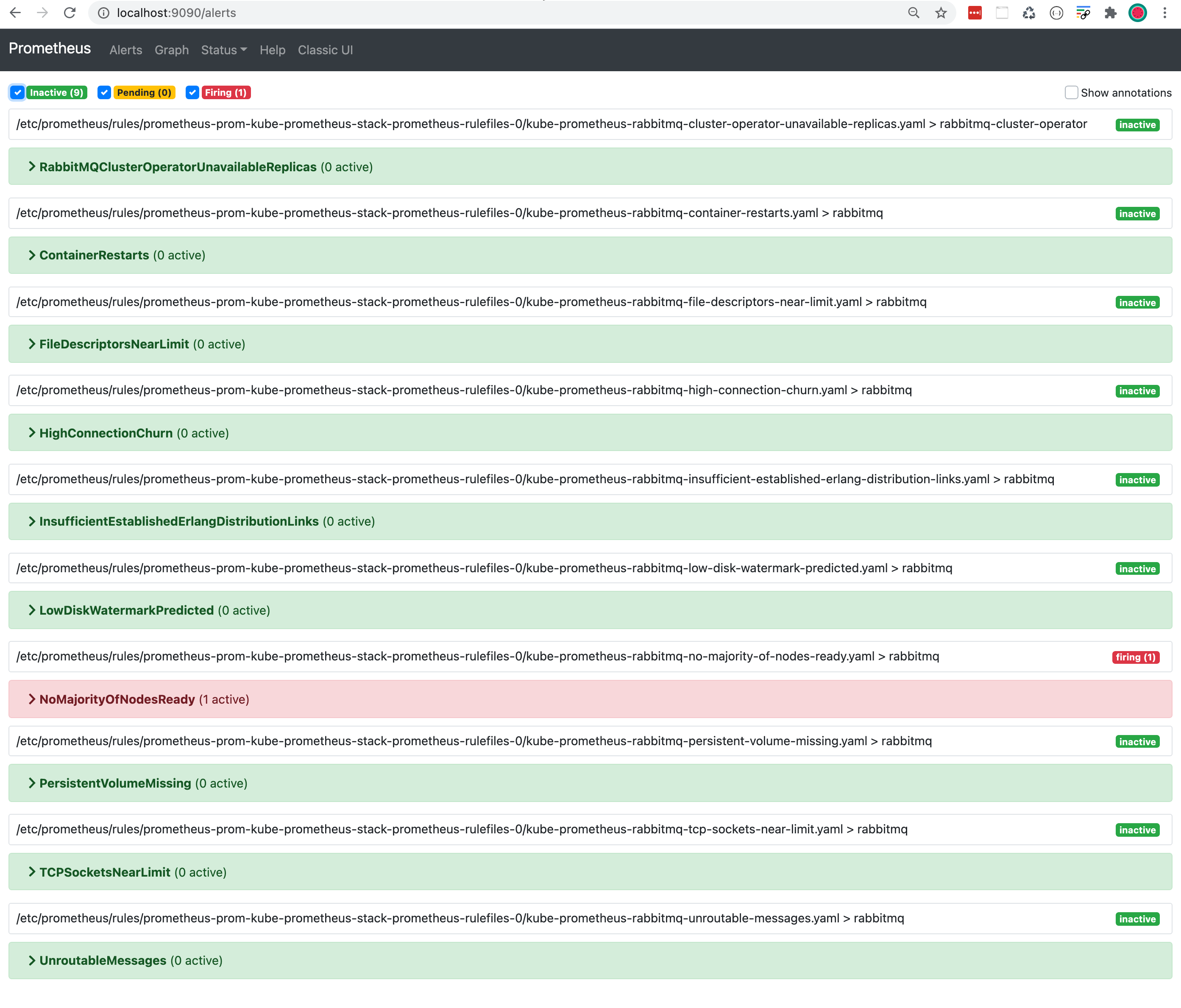
NoMajorityOfNodesReady 警报首先显示为橙色,这意味着它处于 pending 状态。5 分钟后,颜色变为红色,状态变为 firing。这将向 Alertmanager 发送警报。在我们端口转发后(与上述相同),我们打开 Alertmanager UI:https://:9093
kubectl -n kube-prometheus port-forward svc/prom-kube-prometheus-stack-alertmanager 9093
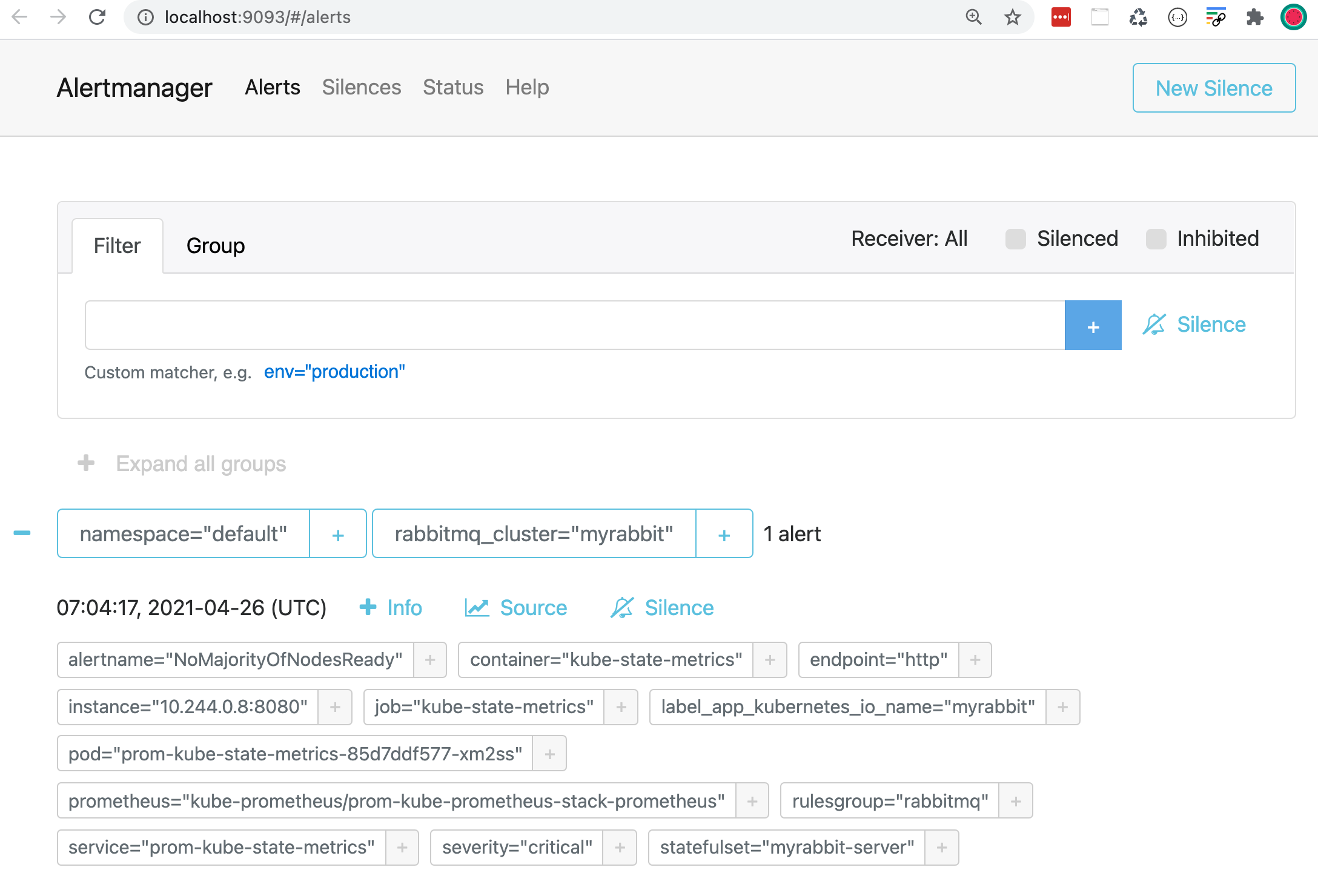
Alertmanager 按 namespace 和 rabbitmq_cluster 对警报进行分组。您会看到一个警报,Alertmanager 会将其转发到您配置的 Slack 频道

恭喜,您触发了您的第一个 RabbitMQ 警报!要解决警报,请在两个节点上启动 rabbit 应用程序
kubectl exec myrabbit-server-0 --container rabbitmq -- rabbitmqctl start_app
kubectl exec myrabbit-server-1 --container rabbitmq -- rabbitmqctl start_app
警报将在 Prometheus 中转换为绿色,它将从 Alertmanager 中删除,并且 RESOLVED 通知将发送到您的 Slack 频道。
过去和当前的 RabbitMQ 警报
要查看所有 RabbitMQ 集群的过去和当前 RabbitMQ 警报,请查看 RabbitMQ-Alerts Grafana 仪表板:https://:3000/d/jjCq5SLMk(用户名:admin & 密码:admin)
kubectl -n kube-prometheus port-forward svc/prom-grafana 3000:80
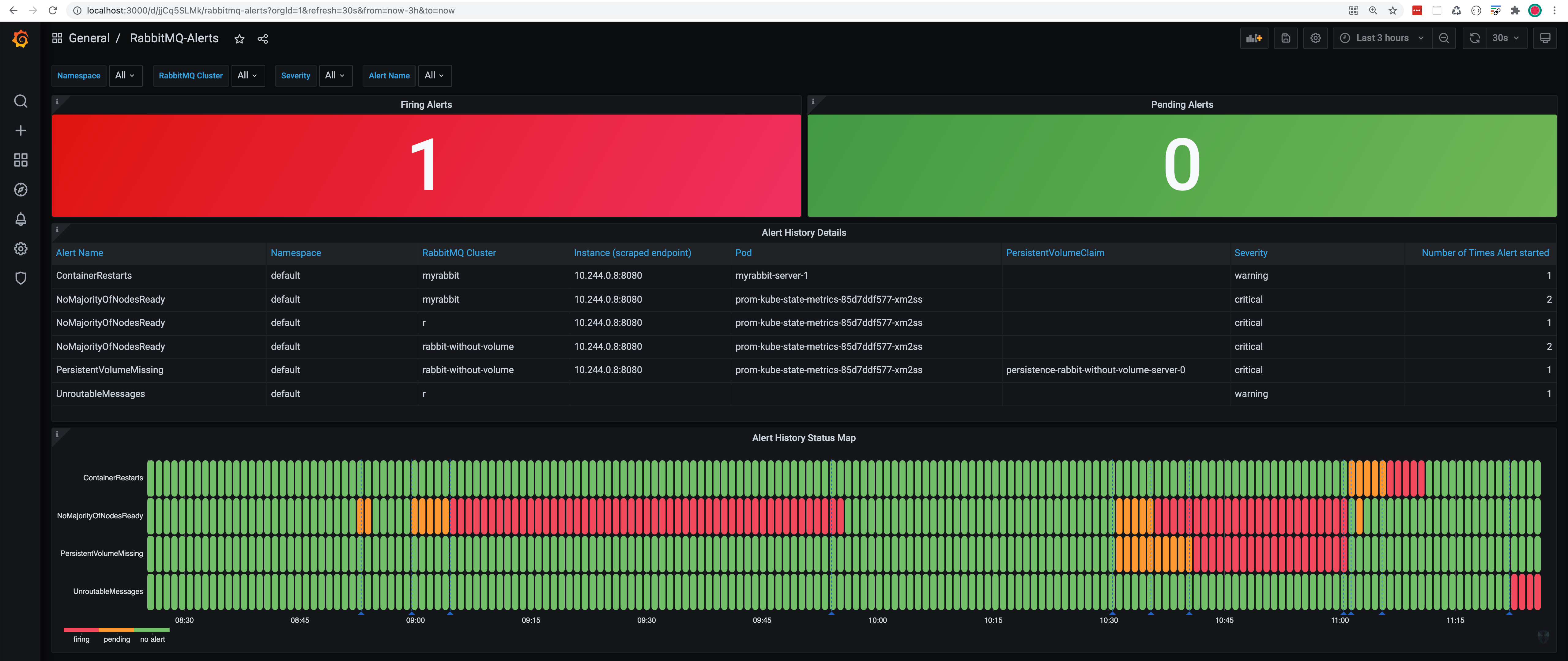
在上面的示例中,我们已在多个 RabbitMQ 集群中触发了多个警报。
您如何提供帮助?
我们分享了我们能想到的最简单和最有用的警报。你们中的一些人已经向我们询问了有关缺少警报的信息,例如内存阈值、Erlang 进程和原子、消息重发等。商业客户向我们询问了运行手册和自动化警报解决。
您对当前的警报规则有何看法?您缺少哪些警报?请通过 GitHub 讨论告知我们。