RabbitMQ 3.11 功能预览:超级流

RabbitMQ 3.11 将带来一个在其历史上拥有最酷名称的功能之一:超级流。超级流是一种通过将大型流划分为较小流来横向扩展的方式。它们与单活动消费者集成,以保留分区内的消息顺序。
这篇博文概述了超级流及其解锁的用例。继续阅读以了解更多信息,我们重视您的反馈,以使此功能尽可能做到最好。
概述
超级流是由单独的、常规的流组成的逻辑流。它是使用 RabbitMQ 流横向扩展发布和消费的一种方式:一个大型逻辑流被划分为分区流,从而分散存储和多个集群节点上的流量。
超级流仍然是一个逻辑实体:由于客户端库的智能性,应用程序将其视为一个“大”流。超级流的拓扑结构基于 AMQP 0.9.1 模型,即交换机、队列以及它们之间的绑定。
下图显示了一个由 3 个分区组成的 invoices 超级流。它由一个 invoices 交换机定义,该交换机绑定了 3 个流。

消息不会通过交换机,而是直接发送到分区流。客户端库使用拓扑信息来确定将消息路由到哪里以及从哪里消费它们。
让我们来谈谈一个显而易见的问题:它与 Kafka 相比如何?我们可以将超级流比作 Kafka 主题,将流比作 Kafka 主题的分区。然而,RabbitMQ 流是一个一流的、单独命名的对象,而 Kafka 分区是 Kafka 主题的下属。这种解释遗漏了很多细节,没有真正的 1 对 1 映射,但对于我们这篇文章中的观点来说已经足够准确了。
超级流还利用单活动消费者来在消费者处理期间保留分区内消息的顺序。下面将详细介绍。
不要误解我们的意思,超级流不会弃用单个流或使其变得无用。它们也不是流的 2.0 版本,因为我们最初就错误地制作了流。超级流位于流的顶部,它们带来了自己的一组特性和功能。您可以继续在适合的地方使用单个流,并且可以探索超级流以满足更苛刻的用例。
发布到超级流
应用程序发布到超级流的消息必须发送到其中一个分区。应用程序可以选择分区,并在客户端库的帮助下完成,broker 不处理路由。这很灵活,并避免了服务器端的瓶颈。
应用程序必须至少提供一条信息:从消息中提取的路由键。以下代码片段显示了应用程序如何使用流 Java 客户端库提供此代码
Producer producer = environment.producerBuilder()
.superStream("invoices") // set the super stream name
.routing(message -> message.getProperties().getMessageIdAsString()) // extract routing key
.producerBuilder()
.build();
producer.send(...);
发布仍然与常规流相同,生产者配置略有不同。发布到流或超级流对应用程序的代码影响不大。
消息会发送到哪里?在这种情况下,库通过使用 MurmurHash3 哈希路由键来选择流分区。此哈希函数提供良好的均匀性、性能和可移植性,使其成为一个良好的默认选择。在我们的示例中,路由键是发票 ID,因此发票应均匀分布在各个分区中。如果路由键是客户 ID,我们将保证给定客户的所有发票都将在同一分区上。这是一个可以利用此功能的用例:在给定时间段内对每个客户进行报告,并使用适当的基于时间戳的偏移规范。
说到处理,让我们看看如何从超级流中消费。
从超级流中消费
超级流的分区是常规流,因此应用程序可以像往常一样从中消费。但这暗示着需要了解超级流的拓扑结构,而我们将其作为逻辑实体出售,应用程序将其视为单个流。幸运的是,客户端库可以在 broker 的一些帮助下做到这一点,从而使应用程序的所有操作都透明。
客户端库可以实现一个众所周知的设计模式,并提供一个复合消费者,该消费者同时从超级流的所有分区中消费
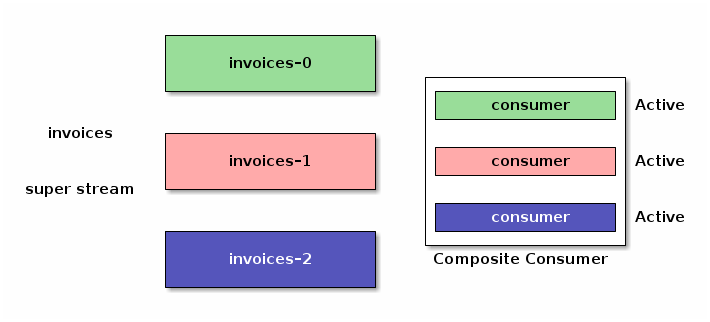
以这种方式实现的复合消费者具有局限性:如果您为了冗余和可伸缩性而启动同一应用程序的多个实例,它们将消费相同的消息,从而复制处理。所有这些都需要协调,幸运的是,我们可以将单活动消费者的语义应用于我们的超级流复合消费者。
现在启用单活动消费者后,我们的复合消费者的实例与 broker 协调,以确保在给定时间一个分区上只有一个消费者。
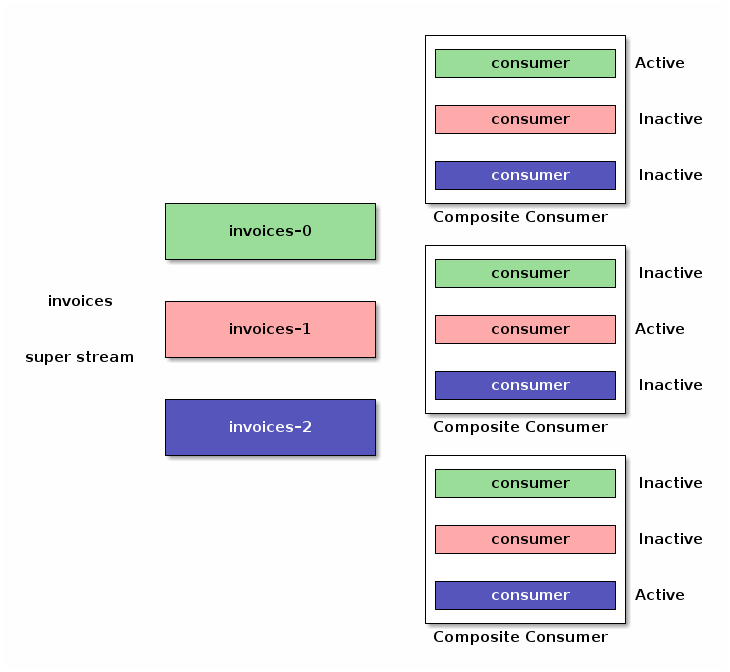
好消息是,所有这些都是实现细节。应用程序实例可以启动和关闭,消费者将根据单活动消费者语义被激活或停用。
这如何转化为代码?这是一个使用流 Java 客户端的示例
Consumer consumer = environment.consumerBuilder()
.superStream("invoices") // set the super stream name
.name("application-1") // set the consumer name (mandatory)
.singleActiveConsumer() // enable single active consumer
.messageHandler((context, message) -> {
// message processing
})
.build();
这与常规流的消费者类似,只有配置发生变化,更重要的是消息处理代码保持不变。
总结
我们在这篇博文中介绍了超级流,这是即将发布的 RabbitMQ 3.11 版本中的一项新功能。超级流是分区流,它们为 RabbitMQ 流带来了可伸缩性。与单活动消费者一起,它们保证在分区内按照发布顺序处理消息。
这篇博文有一个配套示例项目,该项目提供了逐步演示来说明所涵盖的功能。请随时查看!
我们很高兴与 RabbitMQ 社区分享这项新功能,我们迫不及待地想在 RabbitMQ 3.11 今年晚些时候 GA 之前听到一些反馈。