使用原生 MQTT 为数百万客户端提供服务

RabbitMQ 的核心协议一直是 AMQP 0.9.1。为了支持 MQTT、STOMP 和 AMQP 1.0,broker 通过其核心协议透明地进行代理。虽然这是一种使用更多消息协议扩展 RabbitMQ 支持的简单方法,但它会降低可扩展性和性能。
在过去的 9 个月里,我们重写了 MQTT 插件,使其不再通过 AMQP 0.9.1 进行代理。相反,MQTT 插件解析 MQTT 消息并将其直接发送到队列。这就是我们所说的 原生 MQTT。
结果令人瞩目
- 在大量连接的情况下,内存使用量最多可降低 95%,并节省数百 GB。
- RabbitMQ 首次能够处理数百万个连接。
- 端到端延迟降低 50% - 70%。
- 吞吐量增加 30% - 40%。
原生 MQTT 将 RabbitMQ 转变为 MQTT broker,为更广泛的 IoT 用例打开了大门。
原生 MQTT 在 RabbitMQ 3.12 中发布。
概述
如图 1 所示,在 RabbitMQ 3.11 之前的版本中,MQTT 插件的工作方式是解析 MQTT 消息,并通过 AMQP 0.9.1 协议将其转发到通道,然后通道将消息路由到队列。图 1 中的每个蓝点代表一个 Erlang 进程。对于每个传入的 MQTT 连接,总共创建 22 个 Erlang 进程。

每个 MQTT 连接的 16 个 Erlang 进程在 MQTT 插件(即 Erlang 应用程序 rabbitmq_mqtt)中创建,其中包括一个负责 MQTT Keep Alive 的进程和一些充当 AMQP 0.9.1 客户端的进程。
每个 MQTT 连接的 6 个 Erlang 进程在 Erlang 应用程序 rabbit 中创建。它们实现了核心 AMQP 0.9.1 服务器的每个客户端部分。
图 2 显示原生 MQTT 每个传入的 MQTT 连接只需要一个 Erlang 进程。

该单个 Erlang 进程负责解析 MQTT 消息、遵守 MQTT Keep Alive、执行身份验证和授权,以及将消息路由到队列。
常见的 MQTT 工作负载由许多物联网 (IoT) 设备组成,这些设备定期向 MQTT broker 发送数据。例如,可能有成千上万甚至数百万个设备,每个设备每隔几秒或几分钟发送一次状态更新。
我们在去年 RabbitMQ 峰会的演讲“RabbitMQ 性能改进”中了解到,创建 Erlang 进程的成本很低。(Erlang 进程比 Java 线程轻得多。Erlang 进程可以与 Golang 中的 Goroutine 相提并论。)然而,对于 100 万个传入的 MQTT 客户端连接,RabbitMQ 创建 2200 万个 Erlang 进程(在 RabbitMQ 3.11 之前的版本中)还是仅创建 100 万个 Erlang 进程(RabbitMQ 3.12),在可扩展性方面会产生很大的差异。内存使用量和延迟与吞吐量部分分析了这种差异。
不仅 rabbitmq_mqtt 插件被重写,rabbitmq_web_mqtt 插件也被重写。这意味着,从 3.12 版本开始,每个传入的 MQTT over WebSocket 连接也将只有一个 Erlang 进程。因此,本博文中概述的所有性能改进也适用于 MQTT over WebSocket。
术语“原生 MQTT”不是 MQTT 规范的官方术语。“原生 MQTT”指的是新的 RabbitMQ 3.12 实现,其中 RabbitMQ “原生”支持 MQTT,即 MQTT 流量不再通过 AMQP 0.9.1 代理。
新的 MQTT QoS 0 队列类型
原生 MQTT 附带一种新的 RabbitMQ 队列类型,名为 rabbit_mqtt_qos0_queue。要使 MQTT 插件创建这种新队列类型的队列,必须启用同名的 3.12 功能标志 rabbit_mqtt_qos0_queue。(请记住,功能标志不应作为集群配置的一种形式使用。在成功完成滚动升级后,您应该启用所有功能标志。每个功能标志将在未来的 RabbitMQ 版本中成为强制性的。)
在解释新的队列类型之前,我们首先应该了解队列与 MQTT 订阅者之间的关系。
在所有 RabbitMQ 版本中,MQTT 插件为每个 MQTT 订阅者创建一个专用队列。更准确地说,每个 MQTT 连接可能有 0、1 或 2 个队列
- 如果 MQTT 客户端从未发送 SUBSCRIBE 数据包,则 MQTT 连接有 0 个队列。MQTT 客户端仅发布消息。
- 如果 MQTT 客户端使用相同的服务质量 (QoS) 级别创建一个或多个订阅,则 MQTT 连接有 1 个队列。
- 如果 MQTT 客户端使用 QoS 0(最多一次) 和 QoS 1(至少一次) 创建了一个或多个订阅,则 MQTT 连接有 2 个队列。
在列出队列时,您会观察到队列命名模式 mqtt-subscription-<MQTT client ID>qos[0|1],其中 <MQTT client ID> 是 MQTT 客户端标识符,[0|1] 对于 QoS 0 订阅为 0,对于 QoS 1 订阅为 1。为每个 MQTT 订阅者设置单独的队列是有意义的,因为每个 MQTT 订阅者都会收到其自己的应用程序消息副本。
默认情况下,MQTT 插件创建经典队列。
MQTT 插件为 MQTT 订阅客户端透明地创建队列。MQTT 规范未定义队列的概念,MQTT 客户端也不知道这些队列的存在。队列是 RabbitMQ 如何实现 MQTT 协议的实现细节。
图 3 显示了一个 MQTT 订阅者,该订阅者使用 CleanSession=1 连接并使用 QoS 0 订阅。清洁会话意味着 MQTT 会话仅在客户端和服务器之间的网络连接存在期间持续。当会话结束时,服务器中的所有会话状态都会被删除,这意味着队列会被自动删除。
如图 3 所示,每个经典队列都会导致两个额外的 Erlang 进程:一个 supervisor 进程和一个 worker 进程。

rabbit_mqtt_qos0_queue 已禁用新的队列类型优化工作原理如下:如果
- 功能标志
rabbit_mqtt_qos0_queue已启用,并且 - MQTT 客户端使用
CleanSession=1连接,并且 - MQTT 客户端使用 QoS 0 订阅
那么,MQTT 插件将创建 rabbit_mqtt_qos0_queue 类型的队列,而不是经典队列。
图 4 显示,新的队列类型是一种“伪”队列或“虚拟”队列:它与您知道的队列类型(经典队列、quorum 队列和 流)非常不同,因为这种新的队列类型既不是单独的 Erlang 进程,也不在磁盘上存储消息。相反,这种队列类型是 Erlang 进程邮箱的子集。MQTT 消息直接发送到订阅客户端的 MQTT 连接进程。换句话说,MQTT 消息被发送到任何“在线”的 MQTT 订阅者。
更准确地说,应该认为队列被跳过了(如 RabbitMQ 峰会 2022 演讲的幻灯片中的最后一行 no queue at all? 🤔 所示)。将直接向 MQTT 连接进程发送消息实现为队列类型的事实是为了简化消息的路由和协议互操作性,这样消息不仅可以从 MQTT 发布连接进程发送,还可以从通道进程发送。后者使得可以直接从 AMQP 0.9.1、AMQP 1.0 或 STOMP 客户端向 MQTT 订阅者连接进程发送消息,从而跳过专用的队列进程。

rabbit_mqtt_qos0_queue 已启用我们现在了解到,这种新的队列类型跳过了队列进程。但是,在 MQTT 的上下文中这样做有什么优势呢?MQTT 工作负载的特点是许多设备向 broker 发送数据并从 broker 接收数据。以下是按重要性递减顺序排列的四个原因,说明新的队列类型如何提供优化
优势 1:大型扇出
支持大型扇出,将消息从“云”(MQTT broker)发送到所有设备。
对于经典队列和 quorum 队列,每个队列客户端(即通道进程或 MQTT 连接进程)都会为所有目标队列保留状态,以进行流量控制。例如,通道进程在其进程字典中保存来自每个目标队列的信用额度。(阅读我们关于基于信用的流量控制的博文以了解更多信息。)
- 如果有一个通道进程向 300 万个 MQTT 设备发送消息,则在通道进程字典中会保留 300 万个条目(数百 MB 的内存)。
- 如果有 100 个通道进程,每个进程向 300 万个设备发送消息,则进程字典中总共有 3 亿个条目(最好不要尝试这样做)。
- 如果有数千个通道或 MQTT 连接进程,每个进程向 300 万个设备发送消息,RabbitMQ 将耗尽内存并崩溃。
即使这些巨大的扇出极少发生,例如每天一次,从发送 Erlang 进程到所有目标队列的状态也始终保存在内存中(直到目标队列被删除)。
新队列类型最重要的特点是其队列类型客户端是无状态的。这意味着 MQTT 连接或通道进程可以将消息(“fire & forget”)发送到 300 万个 MQTT 连接进程(这仍然暂时需要大量内存),而无需为目标队列保留任何状态。一旦垃圾回收开始,队列客户端进程的内存使用量将降至 0 MB。
优势 2:更低的内存使用量
不仅对于大型扇出,而且在 1:1 拓扑(其中每个发布者向恰好一个订阅者发送消息)中,新的队列类型 rabbit_mqtt_qos0_queue 通过跳过队列进程来节省大量内存。
即使使用 3.12 中的原生 MQTT,在功能标志 rabbit_mqtt_qos0_queue 禁用的情况下,300 万个使用 QoS 0 订阅的 MQTT 设备也会产生 900 万个 Erlang 进程。在功能标志 rabbit_mqtt_qos0_queue 启用的情况下,相同的工作负载仅产生 300 万个 Erlang 进程,因为每个 MQTT 订阅者额外的队列 supervisor 和队列 worker 进程被跳过,从而节省了数 GB 的进程内存。
优势 3:更低的发布者确认延迟
尽管 MQTT 客户端使用 QoS 0 订阅,但另一个 MQTT 客户端仍然可以使用 QoS 1 发送消息(或者等效地,可以将来自 AMQP 0.9.1 发送客户端的通道置于确认模式)。在这种情况下,发布客户端需要来自 broker 的发布者确认。
新队列类型的客户端(MQTT 发布者连接进程或通道进程的一部分)代表“队列服务器进程”直接自动确认,因为最多一次的 QoS 0 消息在从 broker 到 MQTT 订阅者的途中可能会丢失。这导致更低的发布者确认延迟。
在 RabbitMQ 中,只有当所有目标队列都确认收到消息后,消息才会被确认回发布客户端。因此,更重要的是,发布过程仅等待可能具有至少一次消费者的队列的确认。使用新的队列类型,在以下情况下,发布过程不会阻塞向发布客户端发送确认:一条消息被路由到重要的 quorum 队列以及 100 万个 MQTT QoS 0 订阅者,而 100 万个 MQTT 连接进程中的一个超载(因此回复速度会非常慢)。
优势 4:更低的端到端延迟
由于跳过了队列进程,因此消息跳数减少了一次,从而降低了端到端延迟。
过载保护
由于新的队列类型没有流量控制,MQTT 消息到达 MQTT 连接进程邮箱的速度可能比从 MQTT 连接进程传递到 MQTT 订阅客户端的速度更快。当 MQTT 订阅客户端和 RabbitMQ 之间的网络连接较差时,或者在大型扇入场景中,当许多发布者使单个 MQTT 订阅客户端过载时,可能会发生这种情况。
为了防止由于 MQTT QoS 0 消息堆积在 MQTT 连接进程邮箱中而导致的高内存使用率,如果以下两个条件都为真,RabbitMQ 会有意丢弃来自 rabbit_mqtt_qos0_queue 的 QoS 0 消息
- MQTT 连接进程邮箱中的消息数超过设置
mqtt.mailbox_soft_limit(默认为 200),并且 - 发送到 MQTT 客户端的套接字正忙(发送速度不够快)。
请注意,进程邮箱中可能还有其他消息(例如,从 MQTT 订阅客户端发送到 RabbitMQ 的应用程序消息或来自另一种队列类型到 MQTT 连接进程的确认),这些消息显然不会被丢弃。但是,这些其他消息也会计入 mqtt.mailbox_soft_limit。
将 mqtt.mailbox_soft_limit 设置为 0 会禁用过载保护机制,这意味着 RabbitMQ 永远不会有意丢弃 QoS 0 消息。将 mqtt.mailbox_soft_limit 设置为非常高的值会降低有意丢弃 QoS 0 消息的可能性,同时增加导致集群范围 内存告警 的风险(特别是如果消息有效负载很大或存在许多 rabbit_mqtt_qos0_queue 类型的过载队列)。
mqtt.mailbox_soft_limit 可以被认为是 队列长度限制,尽管不完全准确,因为如前所述,Erlang 进程邮箱可以包含 MQTT 应用程序消息以外的其他消息。这就是配置键 mqtt.mailbox_soft_limit 包含单词 soft 的原因。所描述的过载保护机制大致对应于您已经从经典队列和 quorum 队列中了解的溢出行为 drop-head。
队列类型命名
不要依赖这种新队列类型的名称。功能标志 rabbit_mqtt_qos0_queue 的名称不会更改。但是,如果我们决定在其他 RabbitMQ 用例(例如 Direct Reply-to)中重用其部分设计,我们将来可能会更改队列类型 rabbit_mqtt_qos0_queue 的名称。
事实上,MQTT 客户端应用程序和 RabbitMQ 核心(Erlang 应用程序 rabbit)都不知道新的队列类型。最终用户也不会意识到新的队列类型,除非在 Management UI 中或通过 rabbitmqctl 列出队列时。
鉴于我们现在了解了原生 MQTT 的架构和 MQTT QoS 0 队列类型的意图,我们可以继续进行性能基准测试。
内存使用量
本节比较了 RabbitMQ 3.11 中的 MQTT 和 RabbitMQ 3.12 中的原生 MQTT 的内存使用量。完整的测试设置可以在 ansd/rabbitmq-mqtt 中找到。
本节中的两个测试是针对具有以下 RabbitMQ 配置子集的 3 节点集群完成的
mqtt.tcp_listen_options.sndbuf = 1024
mqtt.tcp_listen_options.recbuf = 1024
mqtt.tcp_listen_options.buffer = 1024
management_agent.disable_metrics_collector = true
TCP 缓冲区大小配置为较小,这样它们就不会导致较高的二进制内存使用率。
指标收集在 rabbitmq_management 插件中被禁用。对于生产用例,应使用 Prometheus。rabbitmq_management 插件并非旨在处理大量统计信息发射对象,例如队列和连接。
100 万个 MQTT 连接
第一个测试使用 1,000,000 个 MQTT 连接,这些连接在建立连接后仅发送 MQTT Keep Alive。不发送或接收 MQTT 应用程序消息。
如图 5 所示,3 节点集群在 3.11 中需要 108.0 + 100.7 + 92.4 = 301.1 GiB 的内存,而在 3.12 中仅需要 6.1 + 6.3 + 6.3 = 18.7 GiB 的内存。因此,3.11 比 3.12 多需要 16 倍(或 282 GiB)的内存。原生 MQTT 将内存使用量降低了 94%。

3.11 中导致内存使用量最大的部分是进程内存。如概述部分所述,3.12 中的原生 MQTT 每个 MQTT 连接使用 1 个 Erlang 进程,而 3.11 每个 MQTT 连接使用 22 个 Erlang 进程。3.11 中的某些进程保留了大量状态,导致较高的内存使用率。
原生 MQTT 的低内存使用率不仅通过使用单个 Erlang 进程来实现,还通过减少该单个 Erlang 进程的状态来实现。PR #5895 中实现了许多内存优化,例如从进程状态中删除长列表和不必要的函数引用。
在开发环境中的进一步测试表明,对于总共 900 万个 MQTT 连接,原生 MQTT 在 3 节点集群中每个节点大约需要 56 GB 的内存。
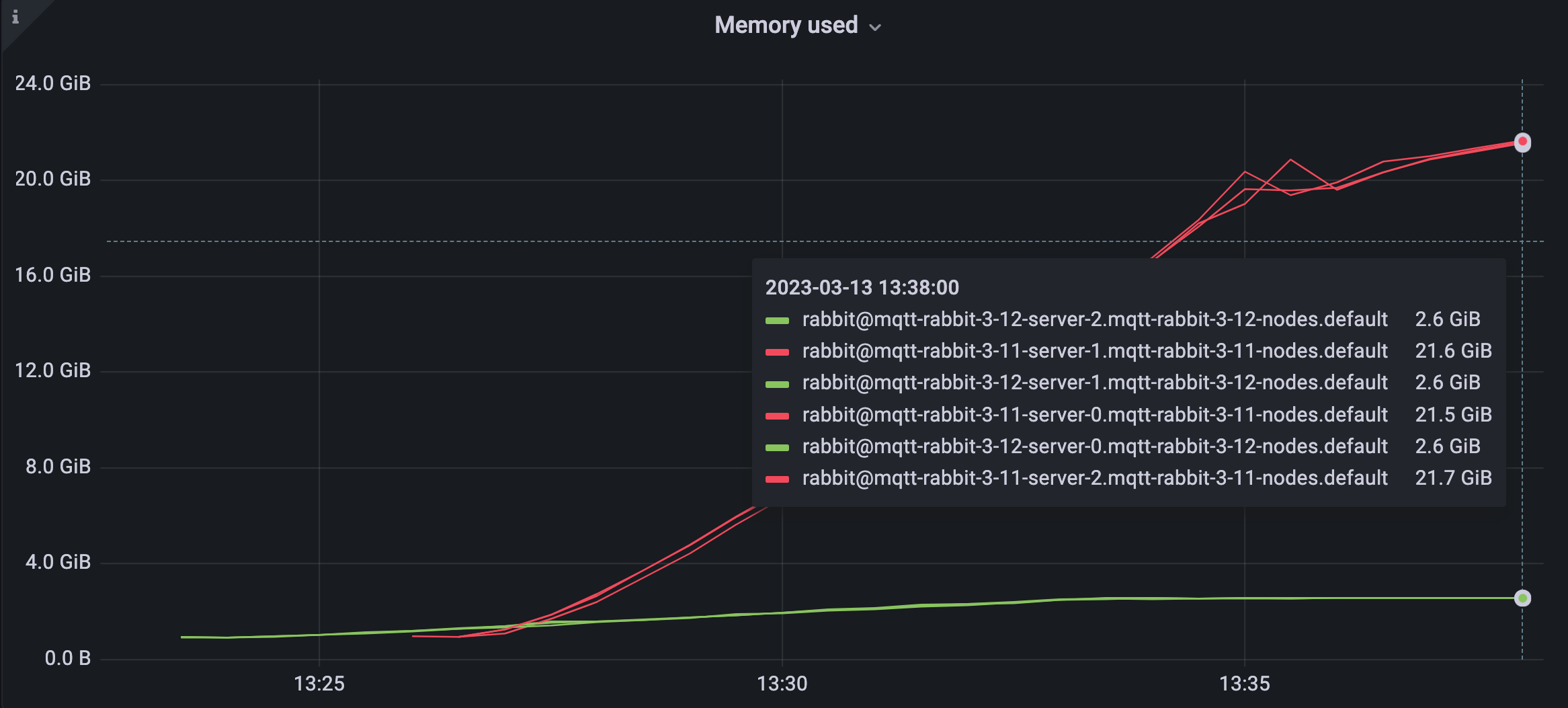
10 万个发布者,10 万个订阅者
第二个测试使用 100,000 个发布者和 100,000 个订阅者。它们在 1:1 拓扑中发送和接收消息,这意味着每个发布者每 2 分钟向恰好一个 QoS 0 订阅者发送一条 QoS 0 应用程序消息。
如图 6 所示,3 节点集群在 3.11 中需要 21.6 + 21.5 + 21.7 = 64.8 GiB 的内存,而在 3.12 中仅需要 2.6 + 2.6 + 2.6 = 7.8 GiB 的内存。
在开发环境中的进一步测试表明,对于以下场景,原生 MQTT 在 3 节点集群中每个节点大约需要 47 GB 的内存
- 总共 300 万个 MQTT 连接
- 1:1 拓扑
- 150 万个发布者每 3 分钟发送一次有效负载为 64 字节的 QoS 1 消息
- 150 万个 QoS 1 订阅者(即 150 万个经典队列 版本 2)
在 RabbitMQ 3.11.6 中发布的 PR #6684 大大降低了许多经典队列的内存使用率,这有利于许多 MQTT QoS 1 或 CleanSession=0 订阅者的用例。
延迟和吞吐量
为了比较 3.11 中的 MQTT 和 3.12 中的原生 MQTT 之间的延迟,我们使用 mqtt-bm-latency。
以下延迟基准测试在具有 8 个 CPU 和 32 GB RAM 的物理 Ubuntu 22.04 机器上执行。客户端和单节点 RabbitMQ 服务器在同一台机器上运行。
在 rabbitmq-server 的根目录中,使用 4 个调度器线程启动服务器
make run-broker PLUGINS="rabbitmq_mqtt" RABBITMQ_CONFIG_FILE="rabbitmq.conf" RABBITMQ_SERVER_ADDITIONAL_ERL_ARGS="+S 4"
服务器使用以下 rabbitmq.conf 运行
mqtt.mailbox_soft_limit = 0
mqtt.tcp_listen_options.nodelay = true
mqtt.tcp_listen_options.backlog = 128
mqtt.tcp_listen_options.sndbuf = 87380
mqtt.tcp_listen_options.recbuf = 87380
mqtt.tcp_listen_options.buffer = 87380
classic_queue.default_version = 2
第一行仅在 RabbitMQ 3.12 中使用,并禁用过载保护,确保所有 QoS 0 消息都传递给订阅者。
3.11 基准测试使用 Git 标签 v3.11.10。3.12 基准测试使用 Git 标签 v3.12.0-beta.2。
延迟和吞吐量 QoS 1
第一个基准测试比较了发送给 QoS 1 订阅者的 QoS 1 消息的延迟和吞吐量。
./mqtt-bm-latency -clients 100 -count 10000 -pubqos 1 -subqos 1 -size 100 -keepalive 120 -topic t
此基准测试使用 100 个 MQTT 客户端“对”,在 1:1 拓扑中发送消息。换句话说,总共有 200 个 MQTT 客户端:100 个发布者和 100 个订阅者。每个发布者向单个订阅者发送 10,000 条消息。
所有 MQTT 客户端并发运行。但是,应用程序消息从发布客户端同步发送到 RabbitMQ:每个发布者发送一条 QoS 1 消息,并等待收到来自 RabbitMQ 的 PUBACK 后再发送下一条消息。
订阅客户端还会为收到的每个 PUBLISH 数据包回复一个 PUBACK 数据包。
上述命令中的主题 t 只是一个主题前缀。每个发布客户端通过将其索引附加到给定的主题来发布到不同的主题(例如,第一个发布者发布到主题 t-0,第二个发布到 t-1 等)。
3.11 的结果
================= TOTAL PUBLISHER (100) =================
Total Publish Success Ratio: 100.000% (1000000/1000000)
Total Runtime (sec): 75.835
Average Runtime (sec): 75.488
Pub time min (ms): 0.167
Pub time max (ms): 101.331
Pub time mean mean (ms): 7.532
Pub time mean std (ms): 0.037
Average Bandwidth (msg/sec): 132.475
Total Bandwidth (msg/sec): 13247.470
================= TOTAL SUBSCRIBER (100) =================
Total Forward Success Ratio: 100.000% (1000000/1000000)
Forward latency min (ms): 0.177
Forward latency max (ms): 94.045
Forward latency mean std (ms): 0.032
Total Mean forward latency (ms): 6.737
3.12 的结果
================= TOTAL PUBLISHER (100) =================
Total Publish Success Ratio: 100.000% (1000000/1000000)
Total Runtime (sec): 55.955
Average Runtime (sec): 55.570
Pub time min (ms): 0.175
Pub time max (ms): 96.725
Pub time mean mean (ms): 5.550
Pub time mean std (ms): 0.031
Average Bandwidth (msg/sec): 179.959
Total Bandwidth (msg/sec): 17995.888
================= TOTAL SUBSCRIBER (100) =================
Total Forward Success Ratio: 100.000% (1000000/1000000)
Forward latency min (ms): 0.108
Forward latency max (ms): 51.421
Forward latency mean std (ms): 0.028
Total Mean forward latency (ms): 2.880
“Total Publish Success Ratio”和“Total Forward Success Ratio”验证了 RabbitMQ 处理了总共 100 个发布者 * 10,000 条消息 = 1,000,000 条消息。
“Total Runtime”和“Average Runtime”显示了第一个巨大的性能差异:使用原生 MQTT,每个发布者在 55 秒内收到来自服务器的所有 10,000 个发布者确认 (PUBACK)。3.11 中的 MQTT 需要 75 秒。
“Pub time mean mean”表明,平均发布者确认延迟从 3.11 中的 7.532 毫秒降低了 1.982 毫秒或 26%,降至 3.12 中的 5.550 毫秒。
如图 7 所示,100 个并发客户端同步发布 MQTT QoS 1 消息到 RabbitMQ 的吞吐量从 3.11 中的每秒 13,247 条消息增加到 3.12 中的每秒 17,995 条消息,增加了每秒 4,748 条消息或 36%。

“转发延迟”统计信息表示端到端延迟,即从发布消息到客户端接收消息所需的时间。它通过让发布者在每个消息有效负载中包含时间戳来衡量。
图 8 说明“Total mean forward latency”从 3.11 中的 6.737 毫秒降低了 3.857 毫秒或 57%,降至 3.12 中的 2.880 毫秒。

延迟 QoS 0
第二个延迟基准测试与第一个非常相似,但对发布的消息使用 QoS 0,对订阅使用 QoS 0。
./mqtt-bm-latency -clients 100 -count 10000 -pubqos 0 -subqos 0 -size 100 -keepalive 120 -topic t
由于客户端使用 CleanSession=1 连接,RabbitMQ 为每个订阅者创建一个 rabbit_mqtt_qos0_queue。因此,队列进程被跳过。
此处省略了 3.11 和 3.12 的发布者结果,因为它们非常低(“Pub time mean mean”为 5 微秒)。发布客户端一次性向服务器发送(“fire & forget”)所有 100 万条消息,而无需等待 PUBACK 响应。
3.11 的结果
================= TOTAL SUBSCRIBER (100) =================
Total Forward Success Ratio: 100.000% (1000000/1000000)
Forward latency min (ms): 3.907
Forward latency max (ms): 12855.600
Forward latency mean std (ms): 883.343
Total Mean forward latency (ms): 7260.071
3.12 的结果
================= TOTAL SUBSCRIBER (100) =================
Total Forward Success Ratio: 100.000% (1000000/1000000)
Forward latency min (ms): 0.461
Forward latency max (ms): 5003.936
Forward latency mean std (ms): 596.133
Total Mean forward latency (ms): 2426.867
“Total mean forward latency”从 3.11 中的 7,260.071 毫秒降低了 4,833.204 毫秒或 66%,降至 3.12 中的 2,426.867 毫秒。
与 QoS 1 基准测试相比,3.11 中的 7.2 秒和 3.12 中的 2.4 秒的端到端延迟非常高,因为 broker 暂时被所有 100 万条 MQTT 消息淹没。
禁用信用流(通过在 advanced.config 中设置 {credit_flow_default_credit, {0, 0}})不会改善 3.11 中的延迟。
留给有兴趣的读者的一个练习是在功能标志 rabbit_mqtt_qos0_queue 禁用的情况下针对 3.12 运行相同的基准测试,以查看跳过队列进程的延迟差异。
3.12 中的原生 MQTT 还有哪些改进?
以下列表包含 3.12 中的原生 MQTT 发生更改的杂项
- 实现了 MQTT 3.1.1 功能,允许 SUBACK 数据包包含失败返回代码 (0x80)。
- AMQP 0.9.1 标头
x-mqtt-dup已被删除,因为其在 MQTT 插件中的使用在 3.11 之前的版本中是错误的。如果您的 AMQP 0.9.1 客户端依赖于此标头,则这是一个重大更改。 - MQTT 插件创建的所有队列都是持久的。这样做是为了简化未来 RabbitMQ 版本中向 Khepri 的过渡。
- MQTT 插件为清洁会话创建独占队列(而不是自动删除队列)。
- MQTT 客户端 ID 跟踪(如果新客户端使用相同的客户端 ID 连接,则终止现有 MQTT 连接)在 pg 中实现。当启用功能标志
delete_ra_cluster_mqtt_node时,用于跟踪 MQTT 客户端 ID 的先前 Ra 集群将被删除。旧的 Ra 集群需要大量内存,并且在一次断开太多客户端连接时成为瓶颈。 - Prometheus 指标是使用 全局计数器 实现的。协议标签的值为
mqtt310或mqtt311。此类指标的一个示例是:rabbitmq_global_messages_routed_total{protocol="mqtt311"} 10。 - MQTT 解析器得到了优化。
- 从未发布过应用程序消息的 MQTT 客户端在 内存和磁盘告警 期间不会被阻止,这样订阅者可以继续清空队列。
我应该将 RabbitMQ 用作 MQTT broker 吗?
原生 MQTT 支持许多新的用例,因为它允许更多数量级的 IoT 设备连接到 RabbitMQ。用例范围很广。
RabbitMQ 只是市场上众多 MQTT broker 之一。还有其他优秀的 MQTT broker,有些将能够处理比 RabbitMQ 更多的 MQTT 客户端连接,因为其他 broker 专门用于 MQTT。
RabbitMQ 的优势在于它不仅仅是一个 MQTT broker。它是一个通用的多协议 broker。RabbitMQ 的真正力量在于协议互操作性与灵活的路由和队列类型选择相结合。
举例来说:作为一家支付处理公司,您可以将分布在世界各地的数十万甚至数百万个收银终端连接到中央 RabbitMQ 集群,其中每个收银终端每隔几分钟向 RabbitMQ 发送 MQTT QoS 1 消息(每当客户进行支付时)。
这些包含支付数据的 MQTT 消息对您的业务至关重要。在任何情况下(节点故障、磁盘故障、网络分区)都不允许消息丢失。它们还需要由一个或多个微服务处理。
一种解决方案是将几个 quorum 队列绑定到主题交换机,其中每个 quorum 队列都绑定到不同的路由键,以便将负载分散到队列中。每个 quorum 队列都在 3 个或 5 个 RabbitMQ 节点之间复制,通过使用底层的 Raft 共识算法来提供高数据安全性。每个 quorum 队列中的消息可以使用比 MQTT 更专业的messaging 协议(如 AMQP 0.9.1 或 AMQP 1.0)由不同的微服务处理。
或者,MQTT 插件可以将 MQTT 支付消息转发到在多个 RabbitMQ 节点之间复制的 super stream。然后,其他客户端可以使用 RabbitMQ Streams protocol 多次从流中消费相同的消息,从而进行不同形式的数据分析。
RabbitMQ 提供的灵活性几乎是无限的,市场上没有其他消息 broker 提供如此广泛的协议互操作性、数据安全性、容错能力、可扩展性和性能。
未来工作
在 3.12 中发布的原生 MQTT 是 RabbitMQ 用作 MQTT broker 的关键一步。但是,MQTT 之旅并未在此结束。在未来,我们计划(不作承诺!)添加以下 MQTT 改进
- 添加对 MQTT 5.0 (v5) 的支持 - 这是社区强烈要求的功能。您可以在 PR #7263 中跟踪当前进度。截至 3.12 版本,RabbitMQ 仅支持 MQTT 3.1.1 (v4) 和 MQTT 3.1.0 (v3)。原生 MQTT 是开发 MQTT 5.0 支持的先决条件。
- 提高在升级处理数百万 MQTT 连接的 RabbitMQ 节点时的弹性,并提高大规模客户端断开连接(例如,由于负载均衡器崩溃)的弹性。
- 支持 QoS 1 的巨大扇出,至少一次向所有设备发送消息。新的队列类型
rabbit_mqtt_qos0_queue通过不在发送和接收 Erlang 进程中保留任何状态来改进大型扇出。但是,截至今天,向数百万个队列发送需要队列确认的消息(MQTT 中的 QoS 1 或 AMQP 0.9.1 中的发布者确认)应格外小心:始终使用相同的发布者,并且非常少见地执行此操作(每隔几分钟)。请注意,1:1 拓扑和大型扇入对于 RabbitMQ 来说没有问题。
总结
虽然 RabbitMQ 在 3.11 版本中已经支持 MQTT,但在客户端连接数量方面的可扩展性一直很差,并且内存使用量过高。
3.12 版本中提供的原生 MQTT 将 RabbitMQ 转变为 MQTT 代理。它允许将数百万客户端连接到 RabbitMQ。即使您不打算连接那么多客户端,通过将您的 MQTT 工作负载升级到 3.12 版本,您也将大幅节省基础设施成本,因为内存使用量最多可降低 95%。
作为下一步,我们计划添加对 MQTT 5.0 的支持。