RabbitMQ 3.12 性能改进

RabbitMQ 3.12 即将发布,其中包含许多新功能和改进。本文重点介绍与性能相关的差异。最重要的变化是经典队列的 lazy 模式现在是默认行为(详见下文)。新实现应该比早期版本中的 lazy 或 non-lazy 实现更节省内存,同时提供更高的吞吐量和更低的延迟。
为了获得更好的性能,我们强烈建议切换到经典队列版本 2 (CQv2)。
概述
让我们快速回顾一下 RabbitMQ 3.12 中最重要的与性能相关的改进。
经典队列:惰性模式的更改
从 3.12 开始,x-queue-mode=lazy 参数将被忽略。所有经典队列现在将具有与之前惰性队列类似的行为。也就是说,消息倾向于写入磁盘,只有一小部分会保留在内存中。内存中的消息数量取决于消费速率。此更改会影响所有经典队列用户。根据我们的测试,对于绝大多数用户来说,新实现应该会带来显著的性能提升,并降低内存使用量。请继续阅读一些基准测试结果,但在升级之前,请务必使用 PerfTest 测试您的系统。
经典队列:大幅改进的经典队列 v2 (CQv2)
此段落已更新,以反映路线图的变化。经典队列版本 2 将成为 RabbitMQ 4.0 中的默认且唯一选项(我们之前计划在 3.13 中将其设为默认)。
自 RabbitMQ 3.10 起,我们有了经典队列的两种实现:原始实现(CQv1)和新实现(CQv2)。它们之间的主要区别在于磁盘存储。
大多数用户仍在使用 CQv1,但从 3.12 开始,我们强烈建议切换到,或至少评估 CQv2。版本 2 将成为 RabbitMQ 4.0 中唯一可用的实现。
迁移过程很简单:在声明队列时,添加一个新的策略键或一个可选的队列参数 x-queue-version=2。要全局切换到 CQv2,请在配置文件中将 classic_queue.default_version 设置为 2。
classic_queue.default_version = 2
可以通过将版本设置回 1 来恢复。每次更改值时,RabbitMQ 都会转换队列的磁盘表示。对于大部分为空的队列,该过程是瞬时的。对于合理的积压消息,可能需要几秒钟。
在许多用例中,切换到 CQv2 可以带来 20-40% 的吞吐量提升,同时降低内存使用量。那些仍然使用经典队列镜像(您不应该这样做,它很快就会被移除!)的用户,需要更彻底地测试您的系统,因为在某些情况下版本 1 与镜像经典队列配合效果更好,但也有许多场景是版本 2 效果更好,尽管它没有任何镜像特定的代码优化。
新的 MQTT 实现:每个连接显著节省内存,支持每个节点数百万个连接
MQTT 插件已经完全重构,提供了更低的内存使用量、更低的延迟,并且比以前可以处理更多的连接。
我们已经发布了另一篇关于 MQTT 相关改进的博客文章。
对仲裁队列的显著改进
在提高仲裁队列效率方面的工作仍在继续。RabbitMQ 3.12 带来了一系列改进,因此所有仲裁队列用户都应该看到更好的性能。在具有长仲裁队列的环境中将观察到最大的变化。以前,随着队列变长,其吞吐量会下降。这现在应该不再是问题了。
节点停止和启动速度更快
具有许多经典队列(数万个或更多)的 RabbitMQ 节点应该停止和启动得更快。这意味着在升级和其他维护操作期间,节点不可用时间更短。
基准测试设置
下面提供的所有数据都比较了 3.11.7 和 3.12-rc.2。一些(主要是较小的)优化已向后移植到较新的 3.11 修补程序版本,这就是为什么此比较不使用最新的 3.11 修补程序版本。
基准测试
在撰写本文时,Team RabbitMQ 的标准性能测试套件包含 14 个测试。每个测试运行 5 分钟。不同的环境同时进行相同的测试,使用不同的消息大小,以便轻松查看消息大小的影响和/或在相同工作负载下比较不同的队列类型或版本。
以下是测试列表,按照它们在 Grafana 仪表板中出现的顺序排列
- 一个发布者尽可能快地发布,而一个消费者尽可能快地消费
- 两个发布者,没有消费者(队列变长时的性能)
- 一个消费者消费上一个测试中的长队列(消费者性能不受发布者影响)
- 五个队列,每个队列有 1 个发布者以 10k 消息/秒的速度发布,1 个消费者(预期的总吞吐量为 50k/秒,我们关注延迟)
- 扇出到 10 个队列 - 1 个发布者和 10 个消费者,一个扇出交换器
- 一个发布者,一个消费者,但只有一个未确认消息(发布者在发送下一条消息之前等待前一条消息的确认)
- 扇入:7000 个发布者每秒发布 1 条消息,到一个队列
- 1000 个发布者每秒发布 10 条消息,每个发布者发布到不同的队列;每个队列也有一个消费者(预期的总吞吐量:10k/秒)
- 一个没有消费者的发布者会创建消息积压,然后加入 10 个消费者来消耗队列
- 与上一个类似,但加入 50 个消费者,但设置了 single-active-consumer(因此只有一个开始消耗队列)
- 与第一个测试类似,但在消费者端使用了 1000 的 multi-ack
- 发布带有 TTL 的消息,并且它们会快速过期(它们永远不会被消费)
- 消息被发布以便稍后被否定确认(这只是为下一个测试做准备)
- 对上一个测试中的消息进行否定确认
最后几个测试不太有趣。它们被引入是为了检查某些特定区域的问题。
环境
这些测试是在以下环境中使用进行的
- 一个具有 e2-standard-16 节点的 GKE 集群
- 使用我们的 Kubernetes Operator 部署的 RabbitMQ 集群,具有以下资源和配置
apiVersion: rabbitmq.com/v1beta1
kind: RabbitmqCluster
metadata:
name: ...
spec:
replicas: 1 # or 3 for mirrored and quorum queues
image: rabbitmq:3.11.7-management # or rabbitmq:3.12.0-rc.2-management
resources:
requests:
cpu: 14
memory: 12Gi
limits:
cpu: 14
memory: 12Gi
persistence:
storageClassName: premium-rwo
storage: "150Gi"
rabbitmq:
advancedConfig: |
[
{rabbit, [
{credit_flow_default_credit,{0,0}}
]}
].
关于环境的一些说明
- 对于许多测试(甚至生产工作负载),这些资源设置都是过多的。这只是我们碰巧用于性能测试的配置,并非推荐
- 您应该能够使用更好的硬件达到更高的值。
e2-standard-16远非最好的硬件。 - 信用流被禁用,因为否则单个快速发布者将被节流(以防止过载并给其他发布者公平的机会);流控制在具有许多用户/连接的系统中很重要,但通常不是我们在进行基准测试时想要的。
测试结果
经典队列的新惰性类默认行为和经典队列 v2
RabbitMQ 的初始版本于 2007 年发布。当时,磁盘访问与任何其他操作相比都非常慢。然而,随着存储技术的不断发展,需要避免将数据写入磁盘的需求越来越少。在 2015 年发布的 3.6.0 版本中,惰性队列被添加为一个选项。惰性队列将所有消息存储在磁盘上以节省内存,这对于可能变长的队列尤其重要。如今,将消息写入磁盘是一项相当便宜的操作(除非您执行 fsync 来保证高数据安全性,如仲裁队列所做的)。通过将消息存储在磁盘上,我们可以使用更少的内存。这意味着更低的成本,更少的内存警报,以及更少由集群中突然的内存峰值引起的麻烦。因此,我们将其作为经典队列的唯一选项。
3.11 非惰性 vs 3.12
让我们从查看用户在升级后使用非惰性经典队列版本 1 (CQv1) 时预期会发生的情况开始。截图来自 12 字节消息大小的测试。

正如您所见,3.12 在所有测试中表现更好:更高的吞吐量,更低的延迟,更低的变异性(速率峰值更少)。同时,3.12 的内存使用率低得多(与惰性队列相似)。在最后一个面板中,您可以看到 3.11 在队列变长时出现内存峰值,而 3.12 在涉及许多连接的测试中内存使用率仅超过 1GB(是连接消耗内存,而不是队列)。
3.12 CQv1 vs CQv2
上面,我们看到了大多数用户在升级到 RabbitMQ 3.12 后应该获得的益处,但这仅仅是开始!让我们将经典队列版本 2 添加到比较中。

使用 CQv2,我们观察到更高的吞吐量和更低的延迟。尤其是在队列变长的第二个测试中,版本 2 的延迟不超过 50ms,而 3.11 可能出现数秒的峰值。
请随时尝试经典队列版本 2。您需要做的就是设置 x-queue-version=2 策略键。要全局切换到 CQv2,请在配置文件中将 classic_queue.default_version 设置为 2。
classic_queue.default_version = 2
版本 2 将成为 RabbitMQ 3.13 的默认版本。
经典镜像队列
如上所述,经典队列版本 1 包含一些专门用于改进队列镜像行为的优化。当我们准备移除镜像功能时,版本 2 不再执行任何特殊的镜像技巧。因此,结果参差不齐,但版本 2 非常高效,即使没有特殊考虑,在大多数情况下也能优于版本 1,即使有镜像。

您可以查看版本 2 是否对您更有效,但更重要的是,请尽快开始迁移到仲裁队列和流。
仲裁队列
仲裁队列多年来一直提供比队列镜像更好的性能和数据安全性,而且它们只会越来越好。
3.12 中最大的改进在于仲裁队列如何处理长积压。

发布到长仲裁队列
在 RabbitMQ 3.12 之前,如果仲裁队列有长积压,发布延迟可能会显著增加,从而降低吞吐量。从 3.12 开始,队列的长度应该不再对延迟和吞吐量产生太大影响。
您可以在第二个测试中看到这一点:虽然两个版本都以大约 25k 消息/秒的速度开始,但 3.11 很快会下降到 10k/秒左右。而 3.12 保持在 20k/秒以上。
3.12 的性能并非如我们所愿的那样顺畅,但已经有了很大的改善,并且可以进一步改进。同样重要的是要记住,在这些测试中,我们实际上是在过载队列:消息以尽可能快的速度持续流入,因此任何垃圾回收或周期性操作(例如 Raft 写前日志滚动)都会表现为延迟峰值。
消费吞吐量
从仲裁队列消费消息也比以前快得多。特别是在从非常长的队列消费消息时,在我们的测试中速度可提高 10 倍。队列仍然应该保持相对较短(如果您需要存储大量消息,可以使用流),但有了这些改进,仲裁队列应该能很好地处理各种消息积压。
查看最后一个面板上的第三个测试(每秒消费消息数)。3.12 开始时超过 15k 消息/秒,并且随着队列变短速度更快。与此同时,3.11 几乎无法超过每秒 1000 条消息。在此测试中,我们正在消费一个积压了 500 万条消息的队列,所以希望您从未见过仲裁队列如此挣扎,但好消息是:即使在这些情况下,仲裁队列现在也应该表现得更好、更可预测。
更可能的情况是消费者在一段时间内不可用,需要追赶。让我们关注这些测试。
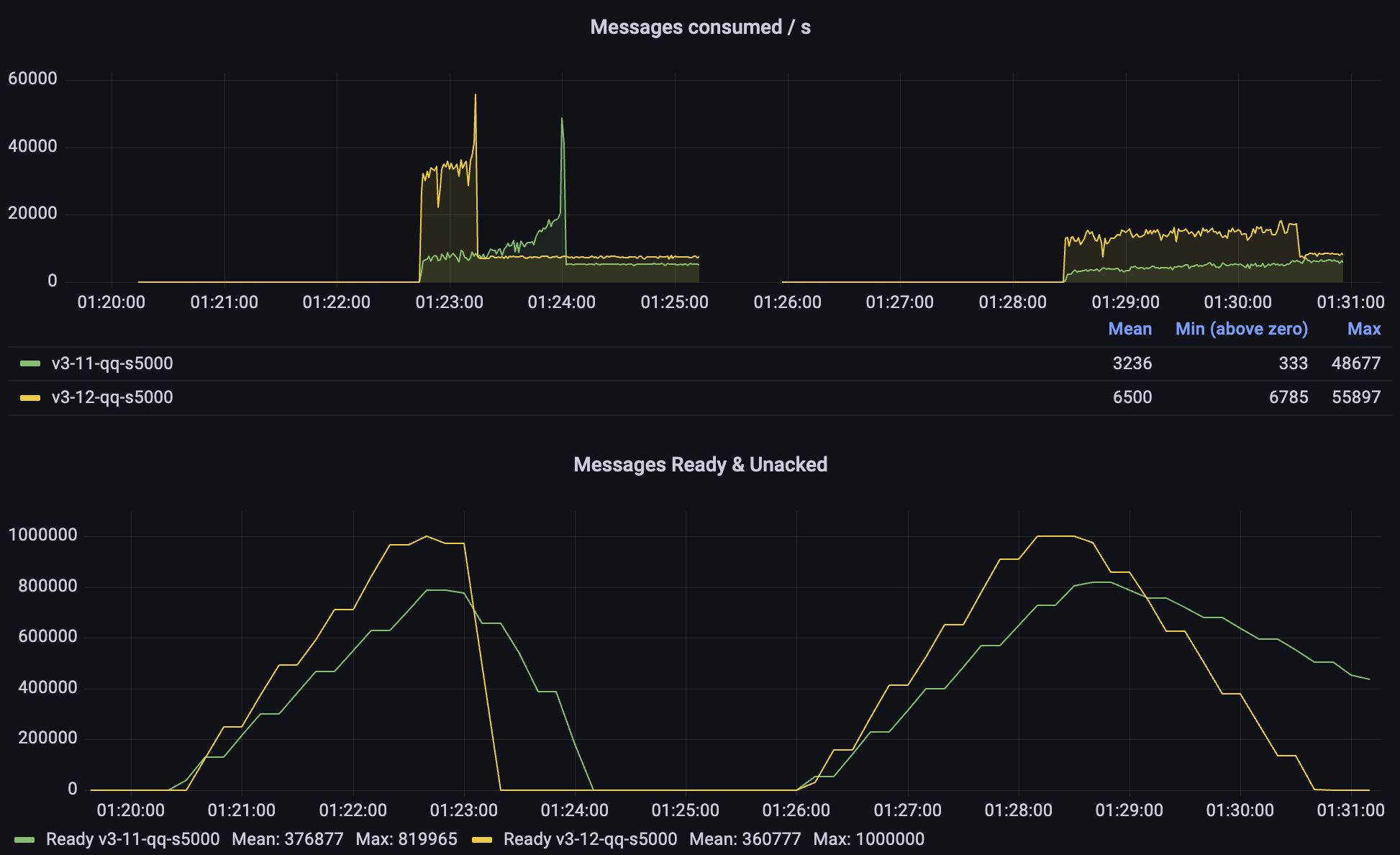
在每个测试的第一个阶段,消费者关闭,并创建消息积压。然后启动消费者。在第一个测试中有 10 个,第二个测试中有 50 个,但只有一个是活动的(作为单个活动消费者)。在这两种情况下,3.12 都提供了显著更高的消费速率,并且队列被更快地消耗。对于 3.11,我们可以看到随着队列积压变短,它会逐渐变快。
节点重启更快
这不应该影响大多数用户,但对于拥有许多经典队列的用户(例如,具有许多订阅的 MQTT 用户)来说,这应该是个好消息。在我们的测试中,我们启动了一个节点,导入了 100,000 个经典队列版本 2,然后重新启动了该节点。3.12 在 3 分钟内启动并运行,而 3.11 需要 15 分钟才能重新开始为客户端提供服务。3.11 在启动时遇到了内存警报,这使得启动过程特别缓慢。有一个客户端正在运行,只是为了查看它何时会断开连接并重新建立连接。

许多空闲队列不再有周期性的资源使用峰值
您可能在上方的截图上注意到,3.11 不仅重启时间长得多,而且发布速率也有波动,即使工作负载很轻(每秒只有 100 条消息)。峰值是由一个内部进程引起的,该进程会检查队列的健康状况以防止发出过时的队列指标。在 3.12 之前,它会查询每个队列的状态来决定队列是否健康。但是,空闲的经典队列会休眠(它们的 Erlang 进程被停止,内存被压缩),并且需要唤醒才能回复它们是健康的。从 3.12 开始,休眠的队列在不唤醒它们的情况下被视为健康的,因此 CPU 和内存使用量应该更低且更一致,即使在节点上有很多队列。
结论
RabbitMQ 3.12 应该会显著提高几乎所有用户的性能。一如既往,我们全心全意地建议您在升级之前测试候选版本和新版本。我们也非常乐意了解人们如何在GitHub Discussions和我们的社区 Discord 服务器上使用 RabbitMQ。
如果您能分享关于您工作负载的信息,最好是以 perf-test 命令的形式,这将有助于我们为您改进 RabbitMQ。