关于内存占用的推理
概述
操作员需要能够推理节点的内存使用情况,包括绝对值和相对值(“什么占用的内存最多”)。这是系统监控的一个重要方面。
本指南重点介绍 RabbitMQ 节点报告的(监控的)内存占用情况,包括内核页面缓存部分,这对于理解流和分区流的上下文非常重要。
此外还有几篇密切相关的指南
RabbitMQ 提供工具来报告和帮助分析节点的内存使用情况
rabbitmq-diagnostics memory_breakdownrabbitmqadmin show memory_breakdown_in_percent和rabbitmqadmin show memory_breakdown_in_bytesrabbitmq-diagnostics observer提供了一个非常精细的、Erlang 进程级别的内存消耗视图- 基于Prometheus 和 Grafana 的监控可以观察内存随时间的变化情况
- Management UI 在节点页面上提供了与
rabbitmq-diagnostics status相同的细分信息 - HTTP API 提供与管理 UI 相同的信息,对于监控非常有用
- rabbitmq-top 和
rabbitmq-diagnostics observer提供了一个更精细的、类似top的、按 Erlang 进程划分的视图
获取节点内存细分应该是推理节点内存使用量的第一步。
请注意,所有测量值都是近似值,基于运行时或内核在特定时间点(通常在 5 秒窗口内)返回的值。
在容器和 Kubernetes 中运行 RabbitMQ
当 RabbitMQ 在使用 cgroups 的环境中运行时,特别是在各种容器化环境和 Kubernetes 中,必须考虑到与内存限制和内核页面缓存相关的某些方面,尤其是在使用流和超级流的集群中。
内存使用量细分
RabbitMQ 节点可以报告其内存使用量细分。细分结果是一个类别列表(如下所示)以及该类别的内存占用情况。
每个类别是该类型的所有进程或表报告的运行时内存占用的总和。这意味着连接类别是所有连接进程使用的内存的总和,通道类别是所有通道进程使用的内存的总和,ETS 表是节点上所有内存中表使用的内存的总和,依此类推。
内存细分如何工作
内存使用量细分报告目标节点上按类别的已分配内存分布
- 连接(进一步分为四个类别:读取器、写入器、通道、其他)
- Quorum queue 副本
- Stream 副本
- 经典队列消息存储和索引
- 二进制堆引用
- 节点本地指标(管理插件统计数据库)
- 内部 schema 数据库表
- 插件,包括传输消息的协议,例如Shovel 和 Federation,以及它们的内部队列
- 已分配但尚未使用的内存
- 代码(字节码、模块元数据)
- ETS(内存键/值存储)表
- Atom 表
- 其他
通常,类别之间没有重叠(没有重复计费)。插件和运行时版本可能会影响此情况。
使用 CLI 工具生成内存使用量细分
内存细分可以使用 CLI 工具生成,包括 rabbitmq-diagnostics 和 rabbitmqadmin v2
- 使用 bash 的 rabbitmq-diagnostics
- 使用 rabbitmqadmin (bash)
- 使用 PowerShell 的 rabbitmq-diagnostics
- 使用 rabbitmqadmin (PowerShell)
rabbitmq-diagnostics memory_breakdown
rabbitmq-diagnostics -n rabbit@hostname memory_breakdown
rabbitmqadmin show memory_breakdown_in_bytes --node rabbit@hostname
rabbitmqadmin show memory_breakdown_in_percent --node rabbit@hostname
rabbitmq-diagnostics.bat memory_breakdown
rabbitmq-diagnostics.bat -n rabbit@hostname memory_breakdown
rabbitmqadmin.exe show memory_breakdown_in_bytes --node rabbit@hostname
rabbitmqadmin.exe show memory_breakdown_in_percent --node rabbit@hostname
这是 rabbitmq-diagnostics memory_breakdown 的示例输出
quorum_queue_procs: 0.4181 gb (28.8%)
binary: 0.4129 gb (28.44%)
allocated_unused: 0.1959 gb (13.49%)
connection_other: 0.1894 gb (13.05%)
plugins: 0.0373 gb (2.57%)
other_proc: 0.0325 gb (2.24%)
code: 0.0305 gb (2.1%)
quorum_ets: 0.0303 gb (2.09%)
connection_readers: 0.0222 gb (1.53%)
other_system: 0.0209 gb (1.44%)
connection_channels: 0.017 gb (1.17%)
mgmt_db: 0.017 gb (1.17%)
metrics: 0.0109 gb (0.75%)
other_ets: 0.0073 gb (0.5%)
connection_writers: 0.007 gb (0.48%)
atom: 0.0015 gb (0.11%)
mnesia: 0.0006 gb (0.04%)
msg_index: 0.0002 gb (0.01%)
queue_procs: 0.0002 gb (0.01%)
reserved_unallocated: 0.0 gb (0.0%)
| 报告字段 | 类别 | 详细信息 |
| total | 由有效内存计算策略(如上所述)报告的总量 | |
| connection_readers | 连接 | 负责连接解析器和大部分连接状态的进程。它们的大部分内存归因于 TCP 缓冲区。节点拥有的客户端连接越多,此类别使用的内存就越多。有关更多信息,请参阅网络指南。 |
| connection_writers | 连接 | 负责序列化出站协议帧和写入客户端连接套接字的进程。节点拥有的客户端连接越多,此类别使用的内存就越多。有关更多信息,请参阅网络指南。 |
| connection_channels | 通道 (Channels) | 客户端连接使用的通道越多,此类别使用的内存就越多。 |
| connection_other | 连接 | 与客户端连接相关的其他内存 |
| quorum_queue_procs | 队列 (Queues) | Quorum queue 进程,包括当前选举出的领导者和跟随者。内存占用量可以在每个队列的基础上进行限制。有关更多信息,请参阅Quorum Queues 指南。 |
| queue_procs | 队列 (Queues) | 经典队列的领导者、索引和内存中保留的消息。入队的数量越多,通常分配给此部分的内存就越多。但这很大程度上取决于队列的类型和属性。有关更多信息,请参阅内存、经典队列。 |
| metrics | Stats DB | 节点本地指标。节点托管的连接、通道、队列越多,需要收集和保留的统计信息就越多。有关更多信息,请参阅管理插件指南。 |
| stats_db | Stats DB | 聚合和预计算的指标、节点间 HTTP API 请求缓存以及所有与统计数据库相关的其他内容。有关更多信息,请参阅管理插件指南。 |
| binaries | 二进制 | 运行时二进制堆。此部分的大部分通常是消息正文和元数据。 |
| plugins | 插件 (Plugins) | Shovel、Federation 等插件,或 STOMP 等协议实现,可能会在内存中累积消息。 |
| allocated_unused | 预分配的内存 | 由运行时分配但尚未使用的内存。 |
| reserved_unallocated | 预分配的内存 | 由内核分配/保留但不是运行时分配/保留的内存 |
| mnesia | 内部数据库 | 虚拟主机、用户、权限、队列元数据和状态、交换器、绑定、运行时参数等。 |
| quorum_ets | 内部数据库 | Raft 实现的 WAL 和其他内存表。其中大部分会定期移至磁盘。 |
| other_ets | 内部数据库 | 一些插件可以使用 ETS 表来存储其状态 |
| code | 代码 | 字节码和模块元数据。这在空白/空节点上只应占用两位数的百分比内存。 |
| other | 其他 | RabbitMQ 无法分类的所有其他进程 |
使用管理 UI 生成内存使用量细分
管理 UI 可用于生成内存细分图。此信息可在节点指标页面上找到,该页面可从“概览”访问

在节点指标页面上,向下滚动到内存细分按钮
内存和二进制堆细分的计算可能成本较高,并且在按下“更新”按钮时按需生成

还可以显示系统中各种项(例如连接、队列)的二进制堆使用量细分
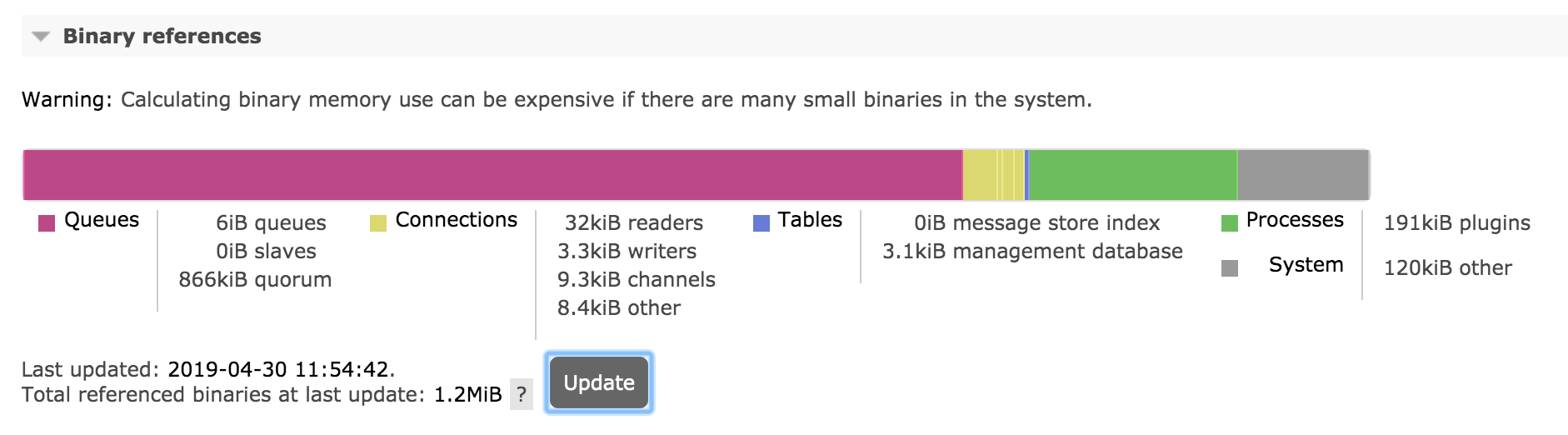
使用 HTTP API 和 curl 生成内存使用量细分
可以通过向 /api/nodes/{node}/memory 端点发出 GET 请求,使用HTTP API 来生成内存使用量细分。
curl -s -u guest:guest http://127.0.0.1:15672/api/nodes/rabbit@mercurio/memory | python -m json.tool
{
"memory": {
"atom": 1041593,
"binary": 5133776,
"code": 25299059,
"connection_channels": 1823320,
"connection_other": 150168,
"connection_readers": 83760,
"connection_writers": 113112,
"metrics": 217816,
"mgmt_db": 266560,
"mnesia": 93344,
"msg_index": 48880,
"other_ets": 2294184,
"other_proc": 27131728,
"other_system": 21496756,
"plugins": 3103424,
"queue_procs": 2957624,
"total": 89870336
}
}
还可以使用 GET 请求向 /api/nodes/{node}/memory 端点检索相对细分。请注意,报告的相对值四舍五入到整数。此端点的目的是用于相对比较(识别贡献最大的类别),而不是精确计算。
curl -s -u guest:guest http://127.0.0.1:15672/api/nodes/rabbit@mercurio/memory/relative | python -m json.tool
{
"memory": {
"allocated_unused": 32,
"atom": 1,
"binary": 5,
"code": 22,
"connection_channels": 2,
"connection_other": 1,
"connection_readers": 1,
"connection_writers": 1,
"metrics": 1,
"mgmt_db": 1,
"mnesia": 1,
"msg_index": 1,
"other_ets": 2,
"other_proc": 21,
"other_system": 19,
"plugins": 3,
"queue_procs": 4,
"reserved_unallocated": 0,
"total": 100
}
}
内存细分类别
连接
这包括客户端连接(包括Shovels 和 Federation links)以及通道,以及出站连接(Shovels 和 Federation 上游链接)使用的内存。大部分内存通常由 TCP 缓冲区使用,在 Linux 上默认自动调整到约 100 kB。TCP 缓冲区大小可以减小,但会以连接吞吐量成比例下降为代价。有关详细信息,请参阅网络指南。
通道也会消耗 RAM。通过优化应用程序使用的通道数量,可以减少该数量。可以使用 channel_max 配置设置限制连接上的最大通道数
channel_max = 16
请注意,一些基于 RabbitMQ 客户端的库和工具可能隐含地需要一定数量的通道。找到最佳值通常是一个试错的过程。
队列和消息
队列、队列索引、队列状态使用的内存。入队的某些消息将为此类别做出贡献。
队列在内存压力下会将其内容交换到磁盘。此行为的确切方式取决于队列属性、客户端发布的消息是持久化的还是瞬时的,以及节点的持久化配置。
消息正文不会在此处显示,而是在“二进制”中显示。
消息存储索引
默认情况下,消息存储使用内存中的索引来存储所有消息,包括已分页到磁盘的消息。插件允许用基于磁盘的实现替换它。
插件
插件使用的内存(不包括 Erlang 客户端,它计入“连接”,以及单独计算的管理数据库)。此类别将包括此处的一些协议插件(如 STOMP 和 MQTT)的每个连接内存,以及 Shovel 和 Federation 等插件入队的内存。
预分配内存
由运行时(VM 分配器)预分配但尚未使用的内存。下面将更详细地介绍这一点。
内部数据库
内部数据库(Mnesia)表会保留其所有数据的内存副本(即使在磁盘节点上)。通常,只有在存在大量队列、交换器、绑定、用户或虚拟主机时,此部分才会很大。插件也可以将数据存储在同一个数据库中。
管理(统计)数据库
统计数据库(如果启用了管理插件)。在集群中,大多数统计信息都存储在节点本地。聚合集群中统计信息所需的跨节点请求可能会被缓存。缓存的数据将在此类别中报告。
二进制
运行时共享二进制数据使用的内存。大部分内存是消息正文和元数据。
对于某些工作负载,二进制数据堆可能不会频繁进行垃圾回收。可以使用 rabbitmqctl force_gc 来强制回收。以下几条命令将强制回收并报告释放最多二进制堆引用的顶级进程
rabbitmqctl eval 'recon:bin_leak(10).'
rabbitmqctl force_gc
对于不支持 rabbitmqctl force_gc 的 RabbitMQ 版本,请使用
rabbitmqctl eval 'recon:bin_leak(10).'
rabbitmqctl eval '[garbage_collect(P) || P <- processes()].'
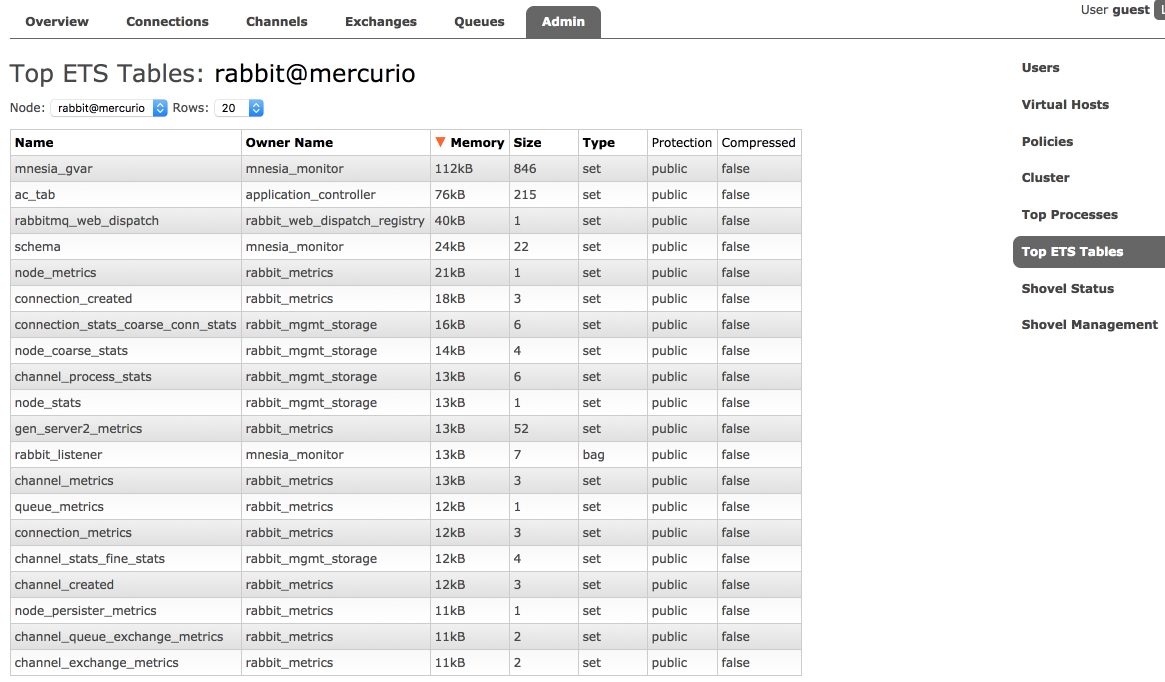
其他 ETS 表
除统计数据库和内部数据库表之外的其他内存表。
代码
代码(字节码、模块元数据)使用的内存。此部分通常相当恒定且相对较小(除非节点完全为空且不存储任何数据)。
Atom
Atom 使用的内存。应该相当恒定。
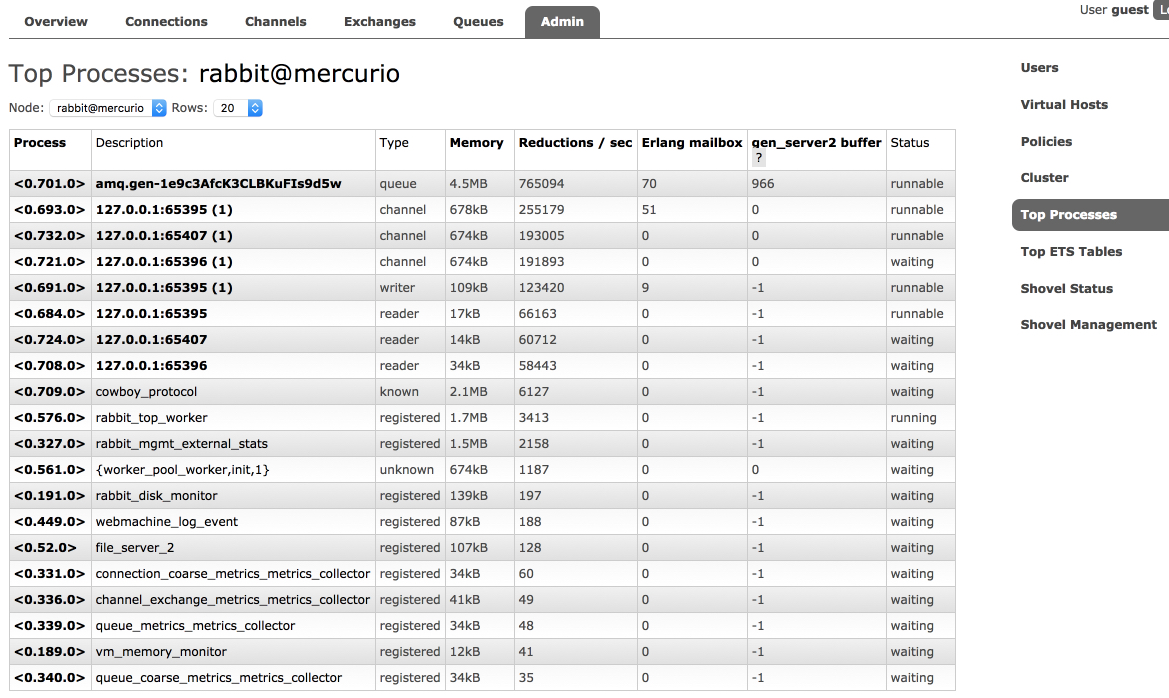
使用 rabbitmq-top 进行按进程分析
rabbitmq-top 是一个插件,有助于识别消耗最多内存或调度器(CPU)时间的运行时进程(“轻量级线程”)。
该插件随 RabbitMQ 一起提供。使用以下命令启用它
[sudo] rabbitmq-plugins enable rabbitmq_top
该插件向管理 UI 添加了新的管理选项卡。一个选项卡按以下指标之一显示顶级进程:
- 使用的内存
- 还原(调度器/CPU 消耗单位)
- Erlang 邮箱长度
- 对于
gen_server2进程,内部操作缓冲区长度
第二个选项卡显示 ETS(内部键/值存储)表。表可以按使用的内存量或行数排序
预分配内存
Erlang 内存细分仅报告当前使用的内存,而不报告已分配供以后使用或被操作系统保留的内存。ps 等 OS 工具可以报告比运行时更多的内存使用量。
这部分内存包括已分配但未使用,以及已由 OS 分配/保留但未使用的部分。这两个值都取决于 OS 和 Erlang VM 分配器设置,并且可能发生显著波动。
这两个部分的值的计算方式取决于 vm_memory_calculation_strategy 设置。如果策略设置为 erlang,则不会报告未使用的内存。如果内存计算策略设置为 allocated,则不会报告由 OS 保留的内存。因此,rss 是提供内核和运行时最多信息的策略。
当一个长期运行的节点报告大量已分配但未使用的内存时,这可能表明运行时内存碎片化。不同的分配器设置可以减少碎片并增加高效使用内存的百分比。正确的设置取决于工作负载和消息有效载荷大小的分布。
可以调整运行时的内存分配器行为,请参阅运行时指南、erl 和 erts_alloc 文档。
内核页面缓存
除了 RabbitMQ 节点直接分配和使用的内存外,该节点读取的文件还可以被操作系统缓存。此缓存可提高 I/O 操作效率,并在 OS 检测到可用内存占比较高时被驱逐(清除)。
使用RabbitMQ streams 的工作负载通常会导致较大的内核页面缓存大小,尤其是在消费者访问跨越数天或数周的消息时。
一些监控工具不将页面缓存的大小包含在进程监控指标中。其他工具则将其添加到进程的驻留集大小(RSS)占用中。这可能会导致混淆:页面缓存不由 RabbitMQ 节点维护或控制。它由操作系统内核维护、控制和驱逐(清除)。
这在 Kubernetes 部署中尤其常见(未使用 cgroup v2)并且使用基于较旧发行版的容器镜像运行 RabbitMQ,这些发行版使用 cgroups v1。
强烈建议使用 Kubernetes 1.25.0(或更高版本)和以下发行版,因为它们采用了更合理的内核页面缓存内存计费方法
- CentOS Stream 9 或更高版本
- Fedora 31 或更高版本
- Ubuntu 21.10 或更高版本
- Debian 11 Bullseye 或更高版本
Red Hat OpenShift 4.12 及更高版本基于 Kubernetes 1.25(或更高版本)。
较大的页面缓存大小能告诉我们关于工作负载的哪些信息?
通常,较大的页面缓存大小仅表示工作负载是 I/O 密集型的,并且可能使用具有大型数据集的流。这并不表示节点存在内存泄漏:当内核检测到系统可用内存不足时,它会清除缓存。
检查容器化环境外的页面缓存(在虚拟机或物理机中)
在非容器化环境(例如,RabbitMQ 节点运行在虚拟机或裸机硬件上)中,使用
cat /proc/meminfo | grep -we "Cached"
来检查内核页面缓存的大小。
检查容器化环境中的页面缓存大小
在 Kubernetes 等容器化环境中,可以使用以下两个 /sys 伪文件系统路径来检查 RSS 和页面缓存的占用情况
cat /sys/fs/cgroup/memory/memory.stat
cat /sys/fs/cgroup/memory/memory.usage_in_bytes
两个关键指标分别称为 rss(驻留集大小)和 cache(页面缓存)。
内存使用量监控
建议生产系统监控所有集群节点的内存使用情况,最好包含细分信息,并结合基础设施级别的指标。通过将细分类别与其他指标(例如,并发连接数或入队消息数)相关联,可以检测到由应用程序特定行为(例如,连接泄漏或没有消费者的队列不断增长)引起的问题。
队列内存
一条消息占用多少内存?
一条消息有多个部分会占用内存
- Payload:>= 1 字节,大小可变,通常从几百字节到几十万字节
- 协议属性:>= 0 字节,大小可变,包含头部、优先级、时间戳、回复至等。
- RabbitMQ 元数据:>= 720 字节,大小可变,包含交换器、路由键、消息属性、持久化、重试状态等。
- RabbitMQ 消息排序结构:16 字节
包含属性和元数据后,具有 1KB 有效载荷的消息将占用 2KB 内存。
某些消息可以存储在磁盘上,但其元数据仍保留在内存中。
一个队列占用多少内存?
一条消息有多个部分会占用内存。每个队列都由一个 Erlang 进程支持。如果队列被复制,每个副本都是一个独立的 Erlang 进程,运行在单独的集群节点上。
由于队列的每个副本,无论是领导者还是跟随者,都是一个单独的 Erlang 进程,因此可以保证消息排序。多个队列意味着多个 Erlang 进程,它们会获得均等的 CPU 时间。这确保了没有队列可以阻塞其他队列。
单个队列的内存使用量可以通过 HTTP API 获取
curl -s -u guest:guest http://127.0.0.1:15672/api/queues/%2f/queue-name |
python -m json.tool
{
..
"memory": 97921904,
...
"message_bytes_ram": 2153429941,
...
}
memory:队列进程使用的内存,占消息元数据(每条消息至少 720 字节),不包含超过 64 字节的消息正文message_bytes_ram:消息正文使用的内存,与大小无关
如果消息较小,消息元数据占用的内存可能比消息正文多。10,000 条载荷为 1 字节的消息将占用 10KB 的 message_bytes_ram(正文)和 7MB 的 memory(元数据)。
如果消息正文较大,则不会反映在队列进程内存中。10,000 条载荷为 100 KB 的消息将占用 976MB 的 message_bytes_ram(正文)和 7MB 的 memory(元数据)。
为什么在发布/消费时队列内存会增长和收缩?
Erlang 为每个 Erlang 进程使用分代垃圾回收。垃圾回收是按队列进行的,与其他 Erlang 进程独立。
当垃圾回收运行时,它会复制使用的进程内存,然后释放未使用的内存。正如这里所示(队列包含大量消息),这可能导致队列进程在垃圾回收期间占用两倍的内存。
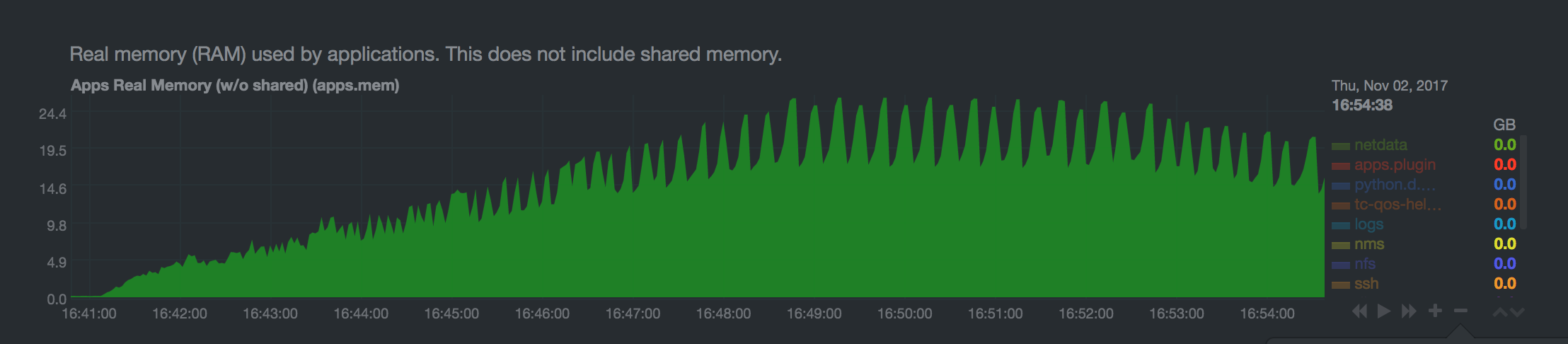
队列内存增长期间的垃圾回收是否值得关注?
如果 Erlang VM 尝试分配比可用内存更多的内存,VM 本身将崩溃或被 OOM killer 杀死。当 Erlang VM 崩溃时,RabbitMQ 将丢失所有非持久化数据。
垃圾回收可能会短暂地使队列使用的内存增加一倍。但是,鉴于
- 垃圾回收过程在不同时间对不同的队列进行
- 并且鉴于在现代 RabbitMQ 版本中,所有类型的队列(经典、quorum、流)要么根本不在内存中存储消息,要么只在内存中存储少量消息
由垃圾回收过程引起的 RabbitMQ 节点总体内存使用量的大幅飙升非常不太可能。
总内存使用量计算策略
RabbitMQ 可以使用不同的策略来计算节点使用了多少内存。历史上,节点从运行时获取此信息,报告使用了多少内存(不仅仅是分配的)。这种策略称为 legacy(erlang 的别名)倾向于低报,不推荐使用。
有效策略通过 vm_memory_calculation_strategy 键进行配置。有两个主要选项
-
rss使用特定于操作系统的手段查询内核以查找节点 OS 进程的 RSS(驻留集大小)值。此策略最精确,在 Linux、MacOS、BSD 和 Solaris 系统上默认使用。使用此策略时,RabbitMQ 会每秒运行短暂的子进程。 -
allocated是一种查询运行时内存分配器信息的策略。它通常非常接近rss策略报告的值。此策略在 Windows 上默认使用。
vm_memory_calculation_strategy 设置也会影响内存细分报告。如果设置为 legacy(erlang)或 allocated,则某些内存细分字段将不会报告。本指南稍后将对此进行更详细的介绍。
以下配置示例使用 rss 策略
vm_memory_calculation_strategy = rss
同样,对于 allocated 策略,请使用
vm_memory_calculation_strategy = allocated
要了解节点正在使用哪种策略,请参阅其有效配置。