监控
概述
本文档提供了与 RabbitMQ 监控相关的各种主题的概述。监控 RabbitMQ 及其使用的应用程序至关重要。监控有助于在问题影响环境的其余部分以及最终影响最终用户之前检测到它们。
我们强烈推荐使用 Prometheus 和 Grafana 的组合来监控 RabbitMQ。
监控是一个广泛的主题。本指南涵盖了几个
- 什么是监控,它为什么重要,存在哪些常见的监控方法
- 可用的监控选项
- 兼容 Prometheus 的外部抓取器,适用于生产集群
- Kubernetes Operator 监控 功能,面向 Kubernetes 用户
- 交互式命令行工具,用于专注的故障排除
- 管理插件的 HTTP API,适用于开发环境
- 哪些 基础架构和内核指标 对监控很重要
- 哪些 RabbitMQ 指标 可用
- 监控会引入 多少开销,以及 应多久 执行一次监控检查?
- 应用程序级别指标
- 如何进行 节点健康检查,以及为什么它比单个命令行命令更复杂
- 部署或升级期间,健康检查用作 节点就绪探测
- 所有节点和应用程序的 日志聚合 与监控密切相关
可以使用许多 常用工具,包括开源和商业工具,来监控 RabbitMQ。如上所述,RabbitMQ 团队推荐大多数用户使用 Prometheus 和 Grafana 的组合。 在 Kubernetes 上,Prometheus 插件由 Kubernetes RabbitMQ Operator 自动启用。 在 Kubernetes 上,Prometheus 插件由 Kubernetes RabbitMQ Operator 自动启用。
什么是监控?
在本指南中,我们将监控定义为通过健康检查和指标随时间推移捕获系统行为的过程。这有助于检测异常:当系统不可用、遇到异常负载、耗尽某些资源或行为不符合其正常(预期)参数时。监控涉及长期收集和存储指标,这不仅对异常检测很重要,对根本原因分析、趋势检测和容量规划也很重要。
监控系统通常与警报系统集成。当监控系统检测到异常时,通常会向警报系统传递某种形式的警报,该警报会通知相关方,例如技术运营团队。
拥有监控意味着更容易检测到系统行为中的重要偏差,从某些区域的服务降级到完全不可用,并且查找根本原因所需的时间大大减少。在没有监控数据的情况下运行分布式系统就像没有 GPS 导航设备或指南针就想走出森林。无论一个人多么聪明或经验丰富,拥有相关信息对于取得良好成果都非常重要。
健康检查在监控中的作用
健康检查是监控的另一个重要方面。健康检查涉及一个或一组命令,它们会 随时间推移 收集被监控系统的一些基本指标,并根据该指标断言系统的状态(健康)。
例如,RabbitMQ 的 Erlang VM 是否正在运行就是一项这样的检查。在这种情况下,指标是“操作系统进程是否正在运行?”。正常运行参数是“进程必须正在运行”。最后,还有一个评估步骤。
当然,健康检查的种类更多。最合适的方式取决于“健康节点”的定义。因此,这是一个系统和团队特定的决定。 RabbitMQ CLI 工具 提供了一些有用的健康检查命令。它们将在 本指南的后续部分 中介绍。
虽然健康检查是一个有用的工具,但它们只能提供有限的系统状态洞察,因为它们的设计侧重于一个或少数几个指标,通常检查单个节点,并且只能在特定时间点上对该节点的状态进行推理。要进行更全面的评估,请 随时间推移 收集更多指标。这可以检测更多类型的异常,因为有些异常只能在更长的时间内识别。这通常由所谓的监控工具完成,而监控工具的种类繁多。本指南介绍了用于 RabbitMQ 监控的一些工具。
系统和 RabbitMQ 指标
一些指标是 RabbitMQ 特有的:它们由 RabbitMQ 节点收集和报告。在本指南中,我们将它们称为“RabbitMQ 指标”。例如,使用的套接字描述符数量、消息总数或节点间通信流量速率。其他指标由 操作系统内核收集和报告。这些指标通常称为系统指标或基础架构指标。系统指标并非 RabbitMQ 特有。例如,CPU 利用率、进程使用的内存量、网络丢包率等。跟踪这两种类型都很重要。单个指标并不总是很有用,但当一起分析时,它们可以提供对系统状态的更全面见解。然后,操作员可以形成关于正在发生什么并需要解决的问题的假设。
基础架构和内核指标
构建有用监控系统的第一步是从基础架构和内核指标开始。其中有相当多的指标,但有些比其他指标更重要。在运行 RabbitMQ 节点或应用程序的所有主机上收集以下指标:
- CPU 统计信息(用户、系统、I/O 等待、空闲百分比)
- 内存使用情况(已用、缓冲、缓存和空闲百分比)
- 内核页面缓存,尤其是在使用 流 的集群中
- 虚拟内存统计信息(脏页刷新、写回量)
- 磁盘 I/O(操作频率、每单位时间传输的数据量、长时间 I/O 操作完成的统计分布、I/O 操作失败率)
- 用于 节点数据目录 的挂载点上的可用磁盘空间
beam.smp使用的文件描述符与 系统最大限制- 按状态划分的 TCP 连接(
ESTABLISHED、CLOSE_WAIT、TIME_WAIT) - 网络吞吐量(接收的字节数、发送的字节数)和最大网络吞吐量
- 网络延迟(集群中所有 RabbitMQ 节点之间,以及与客户端之间)
现有的工具(如 Prometheus 或 Datadog)可以收集、存储和可视化基础架构和内核指标。有很多这样的工具。
使用兼容 Prometheus 的工具进行监控
RabbitMQ 带有内置插件,可公开 Prometheus 格式的指标:rabbitmq_prometheus。该插件公开了 RabbitMQ 指标,包括节点、连接、队列、消息速率等。此插件开销很小,强烈推荐用于生产环境。
与 使用 Prometheus 进行监控 相比,Prometheus 与 Grafana 或 ELK Stack 的组合具有许多优点:
- 监控系统与被监控系统解耦
- 较低的开销
- 长期指标存储
- 访问其他相关指标,例如 运行时 的指标
- 更强大、更可定制的用户界面
- 易于共享指标数据:包括指标状态和仪表板
- 指标访问权限不是 RabbitMQ 特定的
- 收集和聚合节点特定的指标,这对于单个节点故障更具弹性
如何启用它
要启用 Prometheus 插件,请使用
rabbitmq-plugins enable rabbitmq_prometheus
或 预配置 该插件。
HTTP API 端点
默认情况下,该插件在端口 15692 上向与 Prometheus 兼容的抓取器提供指标。
curl {hostname}:15692/metrics
请参阅 Prometheus 插件指南 了解更多信息。
使用管理插件进行监控
内置的 管理插件 也可以收集指标并在 UI 中显示它们。这是开发环境的便捷选择。
该插件还可以为监控工具提供指标。然而,与 使用 Prometheus 进行监控 相比,它有许多显著的限制:
- 监控系统与被监控系统交织在一起
- 使用管理插件进行监控往往开销更大,尤其是在节点 RAM 占用方面
- 它只存储最近的数据(可能是几小时,而不是几天或几个月)
- 它只有一个基本的用户界面
- 其设计 强调易用性而非最佳可用性。
- 管理 UI 访问通过 RabbitMQ 权限标签系统(或 JWT 令牌范围约定)进行控制。
如何启用它
要启用管理插件,请使用
rabbitmq-plugins enable rabbitmq_management
或 预配置 该插件。
HTTP API 端点
默认情况下,该插件通过端口 15672 上的 HTTP API 提供指标,并使用基本 HTTP 身份验证。
curl -u {username}:{password} {hostname}:15672/api/overview
请参阅 管理插件指南 了解更多信息。
监控 Kubernetes Operator 部署的集群
使用 RabbitMQ Kubernetes Operator 部署到 Kubernetes 的 RabbitMQ 集群可以使用 Prometheus 或兼容的工具进行监控。
这在关于 在 Kubernetes 中监控 RabbitMQ 的专用指南中有介绍。
交互式命令行观察工具
rabbitmq-diagnostics observer 是一个类似于 top、htop、vmstat 的命令行工具。它是 Erlang 的 Observer 应用程序 的命令行替代品。它提供了对许多指标的访问,包括单个 运行时 进程的详细状态。
- 运行时版本信息
- CPU 和调度统计信息
- 内存分配和使用统计信息
- 按 CPU(削减次数)和内存使用情况排序的进程
- 网络链接统计信息
- 详细进程信息,如基本 TCP 套接字统计信息
以及更多,以交互式 ncurses 风格的命令行界面显示,并定期更新。
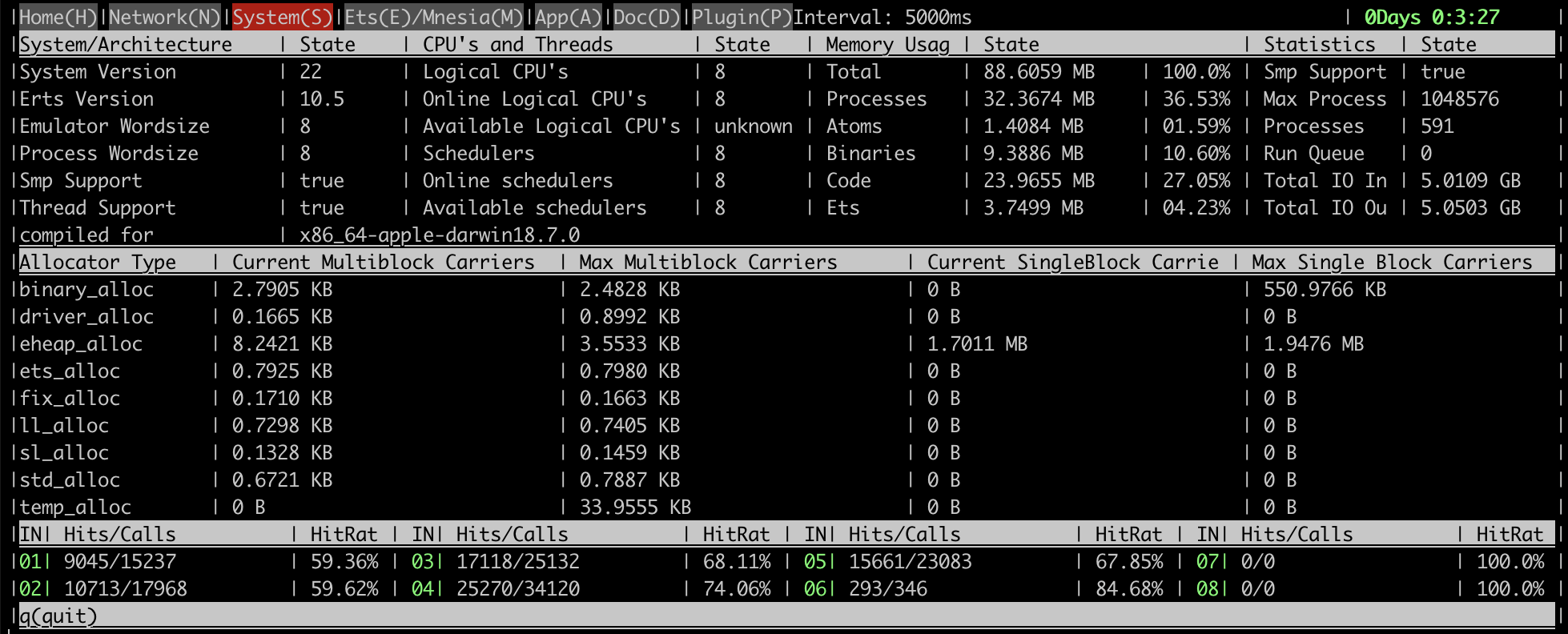
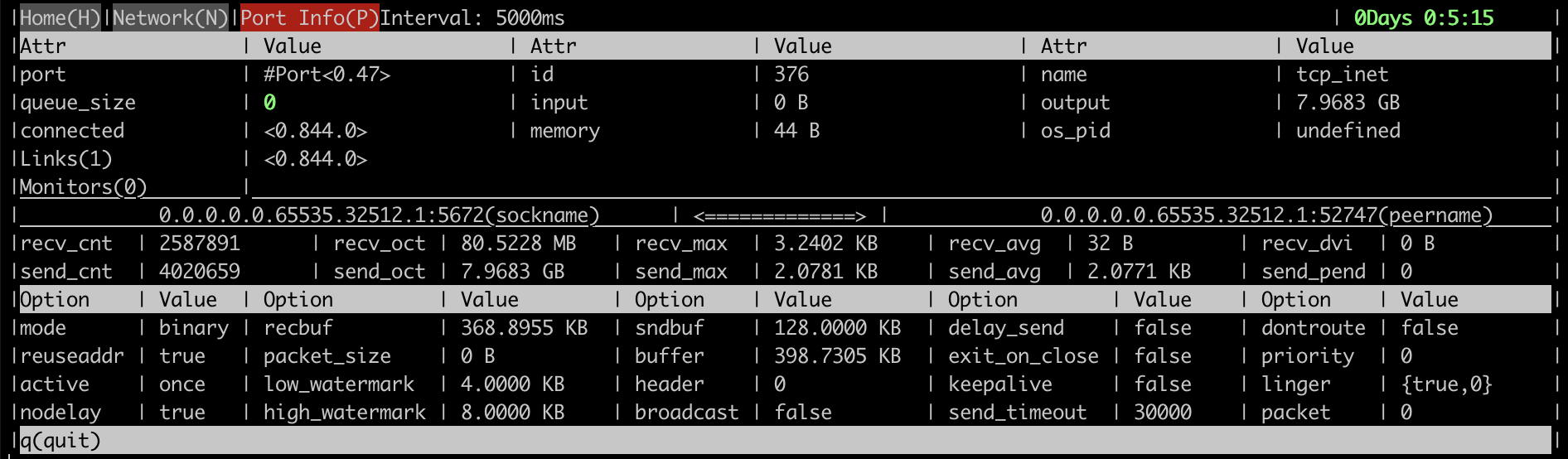
以下是一些屏幕截图,展示了该工具提供的信息类型。
概述页面,包含关键运行时指标
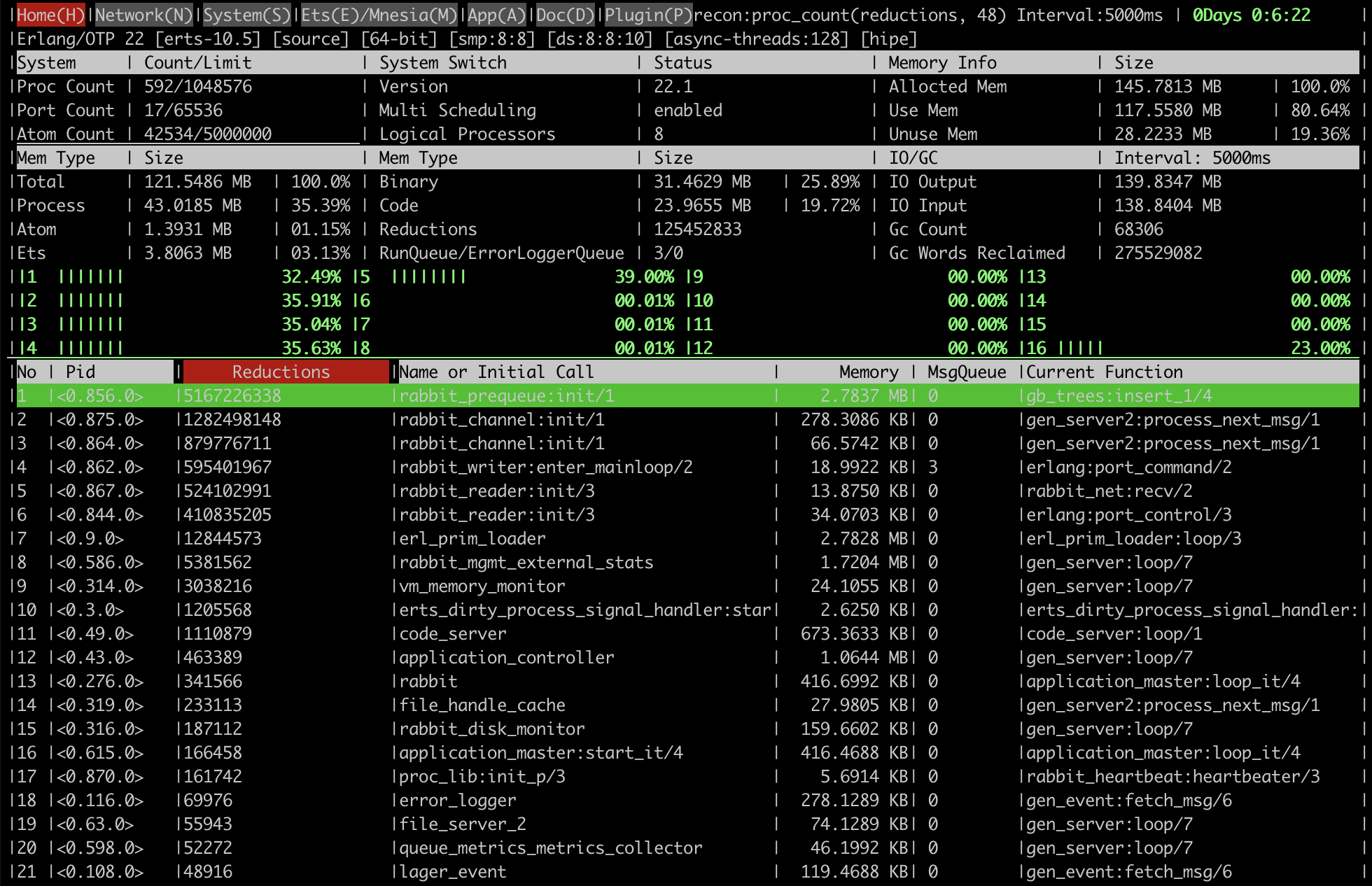
内存分配器统计信息
客户端连接进程指标
监控的资源使用和开销
监控可能会干扰并增加被监控系统的负载。这取决于被监控集群中的实体数量(连接、队列等),但也取决于其他因素:监控频率、监控工具请求多少数据等等。
许多监控系统会定期轮询它们监控的服务。执行的频率因工具而异,但通常可以由操作员配置。
非常频繁的轮询可能对被监控系统产生负面影响。例如,过多的负载均衡器检查(打开到节点的测试 TCP 连接)可能导致 高连接周转率。过度检查 RabbitMQ 中的通道和队列会增加其 CPU 消耗。当节点上有许多(例如数万个)队列时,差异可能很大。
监控工具的另一个常见问题是它们从 RabbitMQ 节点请求多少数据。一些监控工具仅为了获取一个队列的单个指标值就需要查询整个页面或所有队列。这会显着增加监控的 CPU 负载。
可以使用 rabbitmq_top 插件或 rabbitmq-diagnostics observer 来识别这些条件。按削减次数(运行时调度程序时间的单位)排序的前几名进程通常是以下进程之一:
rabbit_mgmt_db_cache_connectionsrabbit_mgmt_external_statsqueue_metrics_metrics_collector- 以及其他名称以
_metrics_collector结尾的进程。
为了减少监控开销,请降低监控频率,并确保监控工具仅查询其所需的数据。
监控频率
生产环境中建议的指标收集间隔是 **30 秒**,或 30 到 60 秒范围内的其他合适值。 Prometheus 导出器 API 设计为每 15 到 30 秒抓取一次,包括生产系统。
在开发环境中,要以更接近实时的时间间隔收集,请使用 5 秒——但不要低于此!
对于速率指标,请使用跨越四次或更多次指标收集间隔的时间范围,以便它可以容忍竞争条件并对抓取失败具有弹性。
RabbitMQ 指标
本节将介绍监控的多个 RabbitMQ 特有方面。本节中提到的大多数指标都由 Prometheus 插件 和管理 UI 公开。
集群范围指标
集群范围指标提供集群状态的高级别视图。其中一些描述了节点之间的交互。此类指标的示例是集群链接流量和检测到的网络分区。其他指标则合并了所有集群成员的指标。连接到所有节点的完整列表就是一个例子。这两种类型都是对基础架构和节点指标的补充。
GET /api/overview 是返回集群范围指标的 HTTP API 端点。
| 指标 | JSON 字段名 |
| 集群名称 | cluster_name |
| 集群范围消息速率 | message_stats |
| 连接总数 | object_totals.connections |
| 通道总数 | object_totals.channels |
| 队列总数 | object_totals.queues |
| 消费者总数 | object_totals.consumers |
| 消息总数(就绪加上未确认) | queue_totals.messages |
| 已准备好进行传递的消息数 | queue_totals.messages_ready |
| 未确认的消息数 | queue_totals.messages_unacknowledged |
| 近期发布的帖子 | message_stats.publish |
| 消息发布速率 | message_stats.publish_details.rate |
| 近期传递给消费者的帖子 | message_stats.deliver_get |
| 消息传递速率 | message_stats.deliver_get_details.rate |
| 其他消息统计信息 |
|
节点指标
有两个 HTTP API 端点提供对节点特定指标的访问:
GET /api/nodes/{node}返回单个节点的状态。GET /api/nodes返回所有集群成员的状态。
后一个端点返回一个对象数组。支持(或可以支持)此作为输入的监控工具应优先使用该端点,因为它减少了请求数量。当不是这种情况时,请依次使用前一个端点来检索每个集群成员的状态。这意味着监控系统知道集群成员列表。
大多数指标代表时间点绝对值。有些代表近期活动(例如,GC 运行和回收的字节数)。后一种指标在与它们的前值和历史平均值/百分位数进行比较时最有用。
| 指标 | JSON 字段名 |
| 使用的 内存总量 | mem_used |
| 内存使用高水位线 | mem_limit |
| 是否存在 内存警报? | mem_alarm |
| 磁盘剩余空间低水位线 | disk_free_limit |
| 是否存在 磁盘警报? | disk_free_alarm |
| 可用的文件描述符 | fd_total |
| 已使用的文件描述符 | fd_used |
| 文件描述符打开尝试次数 | io_file_handle_open_attempt_count |
| 节点间通信链接 | cluster_links |
| GC 运行次数 | gc_num |
| GC 回收的字节数 | gc_bytes_reclaimed |
| Erlang 进程限制 | proc_total |
| 使用的 Erlang 进程数 | proc_used |
| 运行时运行队列 | run_queue |
单个队列指标
单个队列指标可通过 HTTP API 通过 GET /api/queues/{vhost}/{qname} 端点获得。
下表列出了一些可用于监控队列状态的关键指标。其他一些指标(例如队列状态和“空闲时间”)应被视为 RabbitMQ 贡献者使用的**内部指标**。
| 指标 | JSON 字段名 |
| 内存 | memory |
| 消息总数(就绪加上未确认) | 消息 |
| 已准备好进行传递的消息数 | messages_ready |
| 未确认的消息数 | messages_unacknowledged |
| 近期发布的帖子 | message_stats.publish |
| 消息发布速率 | message_stats.publish_details.rate |
| 近期传递的消息 | message_stats.deliver_get |
| 消息传递速率 | message_stats.deliver_get_details.rate |
| 其他消息统计信息 |
|
应用程序级别指标
使用消息传递的系统几乎总是分布式的。在这样的系统中,通常不清楚哪个组件出现故障。系统的每个部分,包括应用程序,都应该被监控和调查。
一些基础架构级别和 RabbitMQ 指标可以显示异常系统行为或问题的存在,但无法确定根本原因。例如,很容易判断一个节点磁盘空间不足,但并不总是容易知道原因。这就是应用程序指标发挥作用的地方:它们可以帮助识别失控的发布者、反复失败的消费者、跟不上速率的消费者,甚至是一个出现延迟的下游服务(例如,消费者使用的数据库中缺少索引)。
一些客户端库和框架提供了注册指标收集器或开箱即用收集指标的方法。 RabbitMQ Java 客户端、Spring AMQP 和 NServiceBus 是一些例子。对于其他库,开发人员必须在他们的应用程序代码中跟踪指标。
应用程序跟踪的指标可能因系统而异,但有些与大多数系统相关:
- 连接打开速率
- 通道打开速率
- 连接失败(恢复)速率
- 发布速率
- 传递速率
- 正面传递确认速率
- 负面传递确认速率
- 平均/第 95 百分位数传递处理延迟
健康检查
健康检查是一种测试 RabbitMQ 服务某个方面是否按预期运行的命令。健康检查 由机器定期执行 或由操作员交互式执行。
健康检查可用于评估节点的运行状态和活力,也可作为部署自动化和编排工具(包括升级期间)的 就绪探测。
有一系列可以执行的健康检查,从最基本的(极少产生 误报)到越来越全面、侵入性和主观的(误报概率更高)。换句话说,健康检查越全面,结果就越不确定。
健康检查可以验证单个节点(节点健康检查)或整个集群(集群健康检查)的状态。
单个节点检查
本节介绍了几种节点健康检查的示例。它们按阶段组织。更高的阶段执行更全面和主观的检查。此类检查的误报概率会更高。某些阶段有专门的 RabbitMQ CLI 工具命令,而其他阶段可能涉及额外的工具。
虽然健康检查是有序的,但更高的编号并不意味着检查“更好”。
健康检查可以有选择地使用和组合。除非另有说明,否则检查应遵循与指标收集相同的 监控频率 建议。
RabbitMQ 的早期版本使用了一种 侵入性健康检查,该检查已被弃用,应避免使用。请使用本节涵盖的检查之一(或它们的组合)。
第一阶段
最基本的检查可确保 运行时 正在运行,并且(间接)CLI 工具可以 认证。
除 CLI 工具认证部分外,误报的概率可视为接近 0,除非在升级和维护窗口期间。
rabbitmq-diagnostics ping 执行此检查。
rabbitmq-diagnostics -q ping
# => Ping succeeded if exit code is 0
第二阶段
一项更全面的检查是执行 rabbitmq-diagnostics status 状态。
这包括第一阶段的检查,并检索一些重要的系统信息,这些信息对其他检查很有用,并且只要 RabbitMQ 在节点上运行(见下文)就应该始终可用。
rabbitmq-diagnostics -q status
# => [output elided for brevity]
这是检查节点的常用方法。误报的概率可视为接近 0,除非在升级和维护窗口期间。
第三阶段
包括之前的检查,并验证 RabbitMQ 应用程序是否正在运行(未通过 rabbitmqctl stop_app 或 暂停少数分区处理策略 停止),并且没有资源警报。
# lists alarms in effect across the cluster, if any
rabbitmq-diagnostics -q alarms
rabbitmq-diagnostics check_running 是一项检查,可确保运行时正在运行,并且节点上的 RabbitMQ 应用程序未停止或暂停。
rabbitmq-diagnostics check_local_alarms 检查节点上是否没有本地警报。如果有任何警报,它将以非零状态退出。
这两个命令组合起来可以实现第三阶段的检查。
rabbitmq-diagnostics -q check_running && rabbitmq-diagnostics -q check_local_alarms
# if both checks succeed, the exit code will be 0
误报的概率较低。接近 高运行时内存水位线 的系统将有很高的误报概率。在升级和维护窗口期间,误报率可能会显着增加。
特别是对于内存警报,可以使用 GET /api/nodes/{node}/memory HTTP API 端点进行额外检查。在下面的示例中,其输出被管道传输到 jq。
curl --silent -u guest:guest -X GET http://127.0.0.1:15672/api/nodes/rabbit@hostname/memory | jq
# => {
# => "memory": {
# => "connection_readers": 24100480,
# => "connection_writers": 1452000,
# => "connection_channels": 3924000,
# => "connection_other": 79830276,
# => "queue_procs": 17642024,
# => "plugins": 63119396,
# => "other_proc": 18043684,
# => "metrics": 7272108,
# => "mgmt_db": 21422904,
# => "mnesia": 1650072,
# => "other_ets": 5368160,
# => "binary": 4933624,
# => "msg_index": 31632,
# => "code": 24006696,
# => "atom": 1172689,
# => "other_system": 26788975,
# => "allocated_unused": 82315584,
# => "reserved_unallocated": 0,
# => "strategy": "rss",
# => "total": {
# => "erlang": 300758720,
# => "rss": 342409216,
# => "allocated": 383074304
# => }
# => }
# => }
它生成的 详细信息 可以使用 jq 或类似工具将其简化为一个值。
curl --silent -u guest:guest -X GET http://127.0.0.1:15672/api/nodes/rabbit@hostname/memory | jq ".memory.total.allocated"
# => 397365248
rabbitmq-diagnostics -q memory_breakdown 提供对同一类别数据的访问,并支持各种单位。
rabbitmq-diagnostics -q memory_breakdown --unit "MB"
# => connection_other: 50.18 mb (22.1%)
# => allocated_unused: 43.7058 mb (19.25%)
# => other_proc: 26.1082 mb (11.5%)
# => other_system: 26.0714 mb (11.48%)
# => connection_readers: 22.34 mb (9.84%)
# => code: 20.4311 mb (9.0%)
# => queue_procs: 17.687 mb (7.79%)
# => other_ets: 4.3429 mb (1.91%)
# => connection_writers: 4.068 mb (1.79%)
# => connection_channels: 4.012 mb (1.77%)
# => metrics: 3.3802 mb (1.49%)
# => binary: 1.992 mb (0.88%)
# => mnesia: 1.6292 mb (0.72%)
# => atom: 1.0826 mb (0.48%)
# => msg_index: 0.0317 mb (0.01%)
# => plugins: 0.0119 mb (0.01%)
# => mgmt_db: 0.0 mb (0.0%)
# => reserved_unallocated: 0.0 mb (0.0%)
第四阶段
包括第三阶段的所有检查,以及对所有已启用监听器的检查(使用临时 TCP 连接)。
要检查节点上启用的所有监听器,请使用 rabbitmq-diagnostics listeners。
rabbitmq-diagnostics -q listeners --node rabbit@target-hostname
# => Interface: [::], port: 25672, protocol: clustering, purpose: inter-node and CLI tool communication
# => Interface: [::], port: 5672, protocol: amqp, purpose: AMQP 0-9-1 and AMQP 1.0
# => Interface: [::], port: 5671, protocol: amqp/ssl, purpose: AMQP 0-9-1 and AMQP 1.0 over TLS
# => Interface: [::], port: 15672, protocol: http, purpose: HTTP API
# => Interface: [::], port: 15671, protocol: https, purpose: HTTP API over TLS (HTTPS)
rabbitmq-diagnostics check_port_connectivity [--address <address>] 是执行上述基本 TCP 连接检查的命令。
# This check will try to open a TCP connection to the discovered listener ports.
# Since nodes can be configured to listen to specific interfaces, an --address should
# be provided, or CLI tools will have to rely on the configured hostname resolver to know where to connect.
rabbitmq-diagnostics -q check_port_connectivity --node rabbit@target-hostname --address <ip-address-to-connect-to>
# If the check succeeds, the exit code will be 0
误报的概率通常较低,但在升级和维护窗口期间可能会显着增加。
第五阶段
包括第四阶段的所有检查,以及检查没有失败的 虚拟主机。
rabbitmq-diagnostics check_virtual_hosts 是一个命令,用于检查是否有任何虚拟主机依赖项可能已失败。这适用于所有虚拟主机。
rabbitmq-diagnostics -q check_virtual_hosts --node rabbit@target-hostname
# if the check succeeded, exit code will be 0
误报的概率通常较低,除非系统处于高 CPU 负载下。
健康检查作为就绪探测
在某些环境中,节点重启由指定的 健康检查 控制。这些检查可验证一个节点已启动,部署过程可以继续到下一个节点。如果检查不通过,则认为节点的部署不完整,部署过程通常会等待并重试一段时间。一个流行的例子是 Kubernetes,其中操作员定义的 就绪探测 可以在使用 OrderedReady pod 管理策略(不建议与 RabbitMQ 一起使用!)或在执行滚动重启时阻止部署。
鉴于 节点重启期间的对等同步行为,此类健康检查可能会阻止集群范围重启及时完成。明确或隐式假设节点已完全启动并重新加入集群对等节点的检查将失败并阻止进一步的节点部署。
此外,大多数 CLI 命令(如 rabbitmq-diagnostics)具有性能影响,因为 CLI 会加入 Erlang 分布(RabbitMQ 节点集群使用的相同机制)。在每次探测执行时加入和离开此集群会产生不必要的开销。
RabbitMQ Kubernetes Operator 将 AMQP 端口的 TCP 端口检查配置为 readinessProbe,并且根本不定义 livenessProbe。这应被视为最佳实践。
集群监控
监控单个节点既容易又直接。
监控集群时,重要的是要理解所使用的 API 端点提供的保证。在集群环境中,每个节点都可以提供指标端点请求。此外,一些指标是节点特定的,而另一些则是集群范围的。
每个节点都提供对其自身的 节点特定指标 的访问。与 基础架构和 OS 指标 类似,必须为每个集群节点收集节点特定的指标。
在它们提供的指标以及集群范围指标的聚合方式方面,Prometheus 和管理插件 API 端点存在重要差异。
Prometheus
使用 Prometheus 插件,每个节点都提供对其 节点特定指标 的访问。Prometheus 查询指标端点 {hostname}:15692/metrics 并存储结果。然后从这些节点特定的数据中计算出集群范围的指标。
管理插件
使用管理插件,每个节点都提供对其自身以及其他集群节点的 节点特定指标 的访问。
集群范围的指标可以从任何 能够与其对等节点通信 的节点获取。该节点将在需要时收集和组合来自其对等节点的数据,然后再生成响应。
使用管理插件时,节点间连接问题将 影响 HTTP API 的行为。为监控请求选择一个随机的在线节点。例如,使用负载均衡器或 轮询 DNS。
已弃用的健康检查和监控功能
旧的侵入性健康检查
RabbitMQ 的早期版本提供了一个单一的、有针对性的侵入性健康检查命令(及其相应的 HTTP API 端点)。
# DO NOT USE: this health check is long deprecated and in modern versions it is a no-op
rabbitmq-diagnostics node_health_check
上述命令 **已弃用** 并且将在 RabbitMQ 的**未来版本中移除**,应避免使用。使用它的系统应改用 精细化的现代健康检查 之一。
上述检查强制系统中的每个连接、队列领导副本和通道发出特定指标。对于大量并发连接和队列,这可能非常消耗资源,并且极有可能产生误报。
上述检查也不适合用作 就绪探测,因为它隐含地假设节点已完全启动。
监控工具
以下是用于收集 RabbitMQ 指标的第三方工具的字母顺序列表。这些工具的能力各不相同,但通常可以收集 基础架构级别 和 RabbitMQ 指标。
请注意,此列表绝非详尽无遗。
| 监控工具 | 在线资源 |
| AppDynamics | |
| AWS CloudWatch | GitHub |
| collectd | GitHub |
| DataDog | |
| Dynatrace | Dynatrace RabbitMQ monitoring |
| Ganglia | GitHub |
| Graphite | 与 Graphite 配合使用的工具 |
| Munin | |
| Nagios | GitHub |
| Nastel AutoPilot | Nastel RabbitMQ Solutions |
| New Relic | New Relic RabbitMQ monitoring |
| Prometheus | |
| Sematext | |
| Zabbix | Zabbix by HTTP, Zabbix by Agent, 博客文章 |
| Zenoss |
日志聚合
日志在排查分布式系统时也非常重要。与指标一样,日志可以提供有助于确定根本原因的重要线索。收集所有 RabbitMQ 节点以及所有应用程序(如果可能)的日志。